¿Qué es el aprendizaje automático?
El aprendizaje automático es una rama de la inteligencia artificial que se enfoca en el desarrollo de algoritmos y modelos estadísticos que permiten que una máquina aprenda a partir de los datos y sea capaz de realizar tareas específicas sin la necesidad de ser programada explícitamente por un humano.
El aprendizaje automático se basa en la idea de que los sistemas informáticos pueden aprender y mejorar de manera autónoma a medida que son expuestos a más datos. El proceso de aprendizaje automático comienza con la recopilación y análisis de grandes conjuntos de datos, los cuales son utilizados para entrenar y ajustar los modelos y algoritmos que permiten que la máquina realice tareas específicas.
Las tareas que puede realizar una máquina a través del aprendizaje automático son diversas, desde la identificación de patrones en datos hasta la realización de predicciones precisas y la toma de decisiones automatizada en tiempo real. El aprendizaje automático es ampliamente utilizado en una variedad de campos, incluyendo finanzas, marketing, salud, seguridad, transporte y muchos otros.
Una aplicación común del aprendizaje automático es la recomendación personalizada de productos o servicios. Por ejemplo, Amazon utiliza el aprendizaje automático para recomendar productos a sus clientes en función de sus preferencias y patrones de compra. Asimismo, las redes sociales utilizan el aprendizaje automático para personalizar la experiencia de usuario y mostrar contenido relevante en el feed de noticias.
En resumen, el aprendizaje automático es una técnica de inteligencia artificial que permite que una máquina aprenda de manera autónoma y sea capaz de realizar tareas específicas sin la necesidad de ser programada explícitamente. Es una herramienta poderosa utilizada en una variedad de campos para mejorar la eficiencia, precisión y personalización de diversas tareas y procesos.
En este tutorial de aprendizaje automático para principiantes, explorarás los siguientes temas:
- ¿Qué es el aprendizaje automático?
- Diferencias entre el aprendizaje automático y la programación tradicional
- ¿Cómo funciona el aprendizaje automático?
- Tipos de algoritmos de aprendizaje automático y sus aplicaciones
- Cómo elegir el algoritmo de aprendizaje automático adecuado
- Desafíos y limitaciones del aprendizaje automático
- Aplicaciones del aprendizaje automático en la vida real
- La importancia del aprendizaje automático
- Preguntas y respuestas comunes en entrevistas de aprendizaje automático
Aprendizaje automático frente a programación tradicional
La programación tradicional difiere significativamente del aprendizaje automático. En la programación tradicional, un programador codifica todas las reglas en consulta con un experto en la industria para la que se desarrolla el software. Cada regla se basa en una base lógica; la máquina ejecutará una salida siguiendo la declaración lógica. Cuando el sistema se vuelve complejo, es necesario escribir más reglas. Puede volverse rápidamente insostenible de mantener.
| Rules (Reglas) | Machine (Máquina)COMPUTER |
| Data (Datos) | Data (Datos) |
| Output (Salida) | Output (Salida) |
| En español | En inglés |
|---|---|
| Aprendizaje automático | Machine learning |
| Datos | Data |
| Salida | Output |
| Computadora | Computer |
| Reglas | Rules |
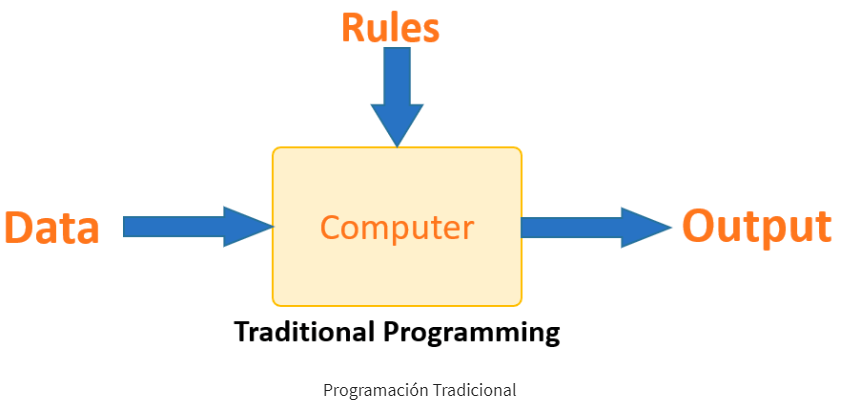
El aprendizaje automático se considera una solución a este problema, ya que la máquina puede aprender a partir de los datos de entrada y salida y, en última instancia, generar una regla por sí misma. A diferencia de la programación tradicional, los programadores no necesitan escribir nuevas reglas cada vez que se agregan nuevos datos. En cambio, los algoritmos pueden adaptarse a nuevas experiencias y datos para mejorar su eficacia con el tiempo.
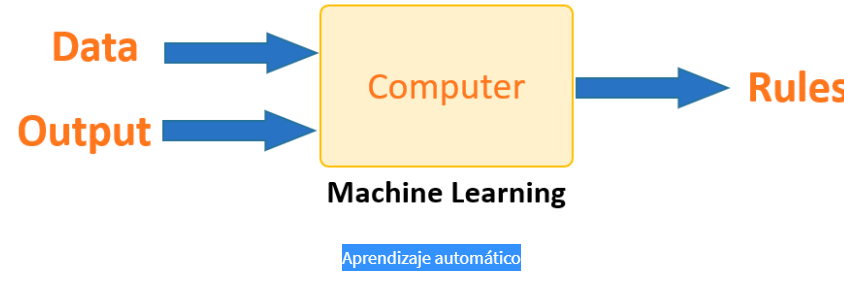
¿Cómo funciona el aprendizaje automático?
Ahora, en este tutorial de conceptos básicos de aprendizaje automático para principiantes, aprenderemos cómo funciona el aprendizaje automático (ML):
El aprendizaje automático es un proceso que tiene lugar en el cerebro de la máquina. La forma en que aprende es similar a la de los seres humanos. Al igual que los humanos, las máquinas aprenden de la experiencia. A medida que aumenta su conocimiento, la capacidad para predecir situaciones también mejora. Si se enfrentan a una situación desconocida, la probabilidad de éxito es menor que en una situación conocida. Para hacer una predicción precisa, la máquina necesita ver ejemplos previos. Cuando se le proporciona un ejemplo similar, puede calcular el resultado.
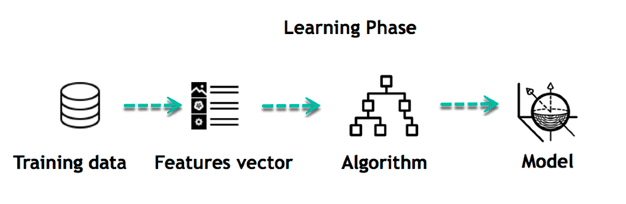
El objetivo principal del aprendizaje automático es aprender y hacer inferencias. En primer lugar, la máquina aprende descubriendo patrones en los datos. Esta tarea se realiza gracias a los datos. Una parte crucial del trabajo de un científico de datos es seleccionar cuidadosamente qué datos proporcionar a la máquina. La lista de atributos utilizados para resolver un problema se llama vector de características. Este vector puede ser considerado como un subconjunto de datos que se utiliza para abordar un problema.
La máquina utiliza algoritmos sofisticados para simplificar la realidad y transformar este descubrimiento en un modelo. De esta manera, la etapa de aprendizaje se utiliza para describir los datos y resumirlos en un modelo.
| English | Español |
|---|---|
| Algorithm | Algoritmo |
| Learning phase | Fase de aprendizaje |
| Training data | Datos de entrenamiento |
| Feature vector | Vector de características |
| Feature vector translation | Traducción del vector de características |
Por ejemplo, la máquina está tratando de comprender la relación entre el salario de un individuo y la probabilidad de ir a un restaurante elegante. Resulta que la máquina encuentra una relación positiva entre el salario y el hecho de ir a un restaurante de lujo: este es el modelo
INFERIR
Cuando se construye el modelo, es posible probar qué tan poderoso es con datos nunca antes vistos. Los nuevos datos se transforman en un vector de características, pasan por el modelo y dan una predicción. Esta es toda la parte hermosa del aprendizaje automático. No es necesario actualizar las reglas ni volver a entrenar el modelo. Puede usar el modelo previamente entrenado para hacer inferencias sobre nuevos datos.
Mira Tambien Matriz de Confusión en el Aprendizaje Automático: con Ejemplos
Matriz de Confusión en el Aprendizaje Automático: con Ejemplos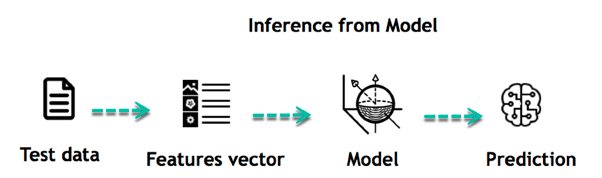
| Español | Inglés |
|---|---|
| Fase de aprendizaje | Learning phase |
| Datos de entrenamiento | Training data |
| Vector de características | Feature vector |
| Algoritmo | Algorithm |
| Modelo | Model |
| Inferencia desde el modelo | Inference from model |
| Datos de prueba | Test data |
| Predicción | Prediction |
La vida de los programas de Machine Learning es sencilla y se puede resumir en los siguientes puntos:
- Definir una pregunta
- Recolectar datos
- Visualizar datos
- Entrenar un algoritmo
- Probar el algoritmo
- Recoger comentarios
- Refinar el algoritmo
- Repetir los pasos 4-7 hasta que los resultados sean satisfactorios
- Utilizar el modelo para hacer predicciones en nuevos datos
Una vez que el algoritmo es capaz de extraer las conclusiones correctas, se puede aplicar ese conocimiento a nuevos conjuntos de datos.
¿Qué son los algoritmos de Machine Learning y dónde se utilizan?
En este tutorial de Machine Learning para principiantes, vamos a aprender sobre los algoritmos de Machine Learning (ML) y donde se utilizan.
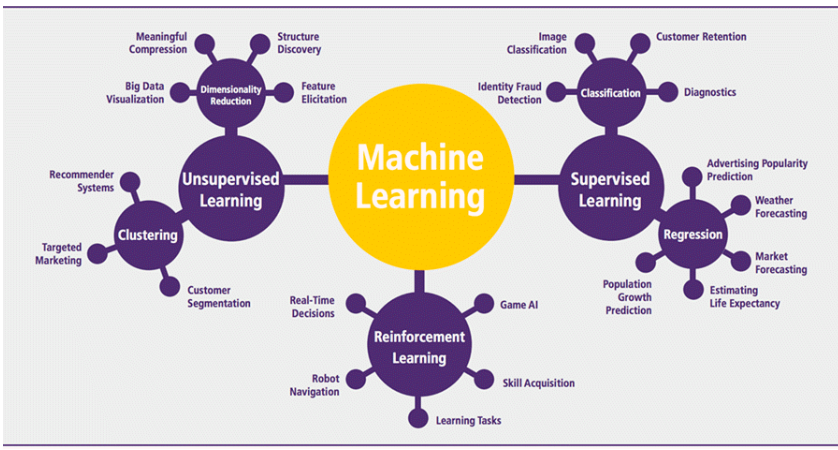
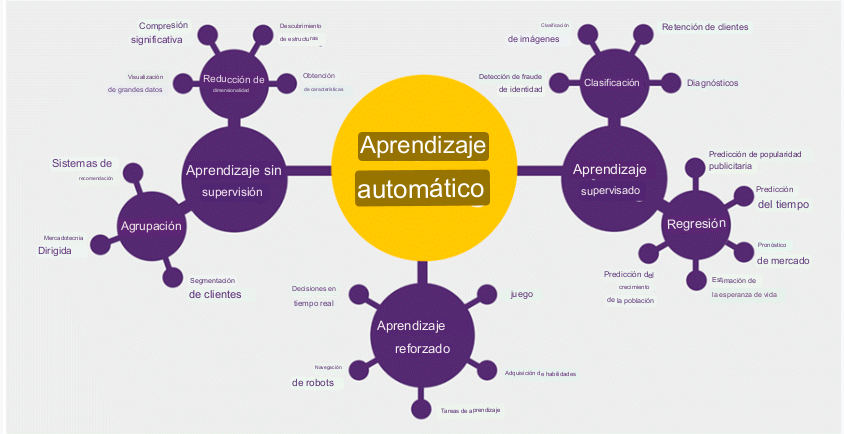
ALGORITMOS DE APRENDIZAJE Automático
El aprendizaje automático se puede clasificar en dos tareas principales: supervisado y no supervisado. Además, existen otros tipos de algoritmos de aprendizaje automático, como el aprendizaje por refuerzo y el aprendizaje semi-supervisado.
Aprendizaje supervisado
Un algoritmo de aprendizaje supervisado utiliza datos de entrenamiento y retroalimentación humana para aprender la relación entre las entradas y las salidas. Por ejemplo, un algoritmo puede utilizar los gastos de marketing y el pronóstico del tiempo como entradas para predecir las ventas de latas. El aprendizaje supervisado se utiliza cuando se conocen los datos de salida y se desea predecir nuevos datos. Se puede clasificar en dos categorías:
- Tarea de clasificación: donde el objetivo es predecir una variable categórica o etiqueta, como sí o no, verdadero o falso, etc.
- Tarea de regresión: donde el objetivo es predecir una variable numérica o continua, como el precio de una casa o la temperatura.
Clasificación
Imagina que deseas predecir ciertas características de un cliente para una campaña publicitaria. Para ello, comenzarás a recopilar datos relevantes como altura, peso, trabajo, salario, historial de compras, etc. de tu base de datos de clientes. En este caso, el objetivo de la clasificación es asignar una etiqueta que represente la probabilidad de que el cliente tenga o no ciertas características en función de la información recopilada. Por ejemplo, si deseas predecir el género de un cliente, el modelo de clasificación asignará una probabilidad de ser hombre o mujer. Si el modelo aprendió a reconocer correctamente los patrones asociados a cada clase, puede usarse para hacer predicciones en nuevos datos. Por ejemplo, si acabas de recibir nueva información de un cliente desconocido y el modelo de clasificación predice hombre = 70%, significa que el algoritmo está seguro en un 70% de que este cliente es hombre y en un 30% es mujer. Las etiquetas pueden ser de dos o más clases, como en el caso de la predicción de objetos, en el que se pueden tener docenas de clases (por ejemplo, vidrio, mesa, zapatos, etc.).
Regresión
Cuando la salida es un valor continuo, la tarea es una regresión. Por ejemplo, un ingeniero civil puede necesitar predecir el costo de construcción de un edificio en función de una variedad de características como el tamaño del terreno, la ubicación, el tipo de estructura, los materiales de construcción, etc. El sistema estará entrenado para estimar el costo de construcción con el menor error posible, lo que permitirá al ingeniero civil tener una idea más precisa de los costos asociados con un proyecto determinado y hacer mejores decisiones en términos de presupuesto y recursos.
| Algoritmo | Descripción | Tipo |
|---|---|---|
| Regresión lineal | Encuentra una manera de correlacionar cada función con la salida para ayudar a predecir valores futuros. | Regresión |
| Regresión logística | Extensión de la regresión lineal que se usa para tareas de clasificación. La variable de salida es binaria (p. ej., solo blanco o negro) en lugar de continua (p. ej., una lista infinita de colores potenciales). | Clasificación |
| Árbol de decisión | Modelo de clasificación o regresión altamente interpretable que divide los valores de características de datos en ramas en los nodos de decisión (p. ej., si una característica es un color, cada color posible se convierte en una nueva rama) hasta que se toma una decisión final. | Clasificación o Regresión |
| Bayesiana ingenua | El método bayesiano es un método de clasificación que hace uso del teorema bayesiano. El teorema actualiza el conocimiento previo de un evento con la probabilidad independiente de cada característica que puede afectar el evento. | Clasificación o Regresión |
| Máquinas de vectores soporte (SVM) | El algoritmo SVM encuentra un hiperplano que dividió de manera óptima las clases. Se utiliza mejor con un solucionador no lineal. | Regresión (no muy común) o Clasificación |
| Bosque aleatorio | El algoritmo se basa en un árbol de decisión para mejorar drásticamente la precisión. Random forest genera muchas veces árboles de decisión simples y utiliza el método de «voto mayoritario» para decidir qué etiqueta devolver. Para la tarea de clasificación, la predicción final será la más votada; mientras que para la tarea de regresión, la predicción promedio de todos los árboles es la predicción final. | Clasificación o Regresión |
| AdaBoost | Técnica de clasificación o regresión que utiliza una multitud de modelos para llegar a una decisión, pero los sopesa en función de su precisión para predecir el resultado. | Clasificación o Regresión |
| Árboles que aumentan el gradiente | Los árboles potenciadores de gradientes son una técnica de clasificación/regresión de última generación. Se centra en el error cometido por los árboles anteriores y trata de corregirlo. | Clasificación o Regresión |
Aprendizaje sin supervisión
En el aprendizaje no supervisado, un algoritmo explora los datos de entrada sin que se le proporcione una variable de salida explícita (por ejemplo, explorando los datos demográficos de los clientes para identificar patrones).
Se utiliza cuando no se dispone de información de salida etiquetada y se busca encontrar patrones o estructuras ocultas en los datos. El objetivo es descubrir información útil en los datos y agruparlos en categorías o clústeres similares, o reducir la dimensionalidad de los datos para facilitar su análisis.
| Nombre del algoritmo | Descripción | Tipo |
|---|---|---|
| Agrupamiento de K-medias | Coloca los datos en algunos grupos (k) que contienen datos con características similares (según lo determinado por el modelo, no de antemano por humanos) | Agrupación |
| Modelo de mezcla gaussiana | Una generalización del agrupamiento de k-medias que brinda más flexibilidad en el tamaño y la forma de los grupos (conglomerados) | Agrupación |
| Agrupación jerárquica | Divide los clústeres a lo largo de un árbol jerárquico para formar un sistema de clasificación. Se puede utilizar para el cliente de tarjeta de fidelización de clúster | Agrupación |
| Sistema de recomendación | Ayuda a definir los datos relevantes para hacer una recomendación. | Agrupación |
| PCA/T-SNE | Se utiliza principalmente para disminuir la dimensionalidad de los datos. Los algoritmos reducen el número de características a 3 o 4 vectores con las varianzas más altas. | Reducción de dimensiones |
Cómo elegir el algoritmo de aprendizaje automático
En este tutorial básico de aprendizaje automático, aprenderemos cómo elegir el algoritmo de aprendizaje automático (ML). Hay muchos algoritmos de aprendizaje automático, y la elección del algoritmo adecuado depende del objetivo específico.
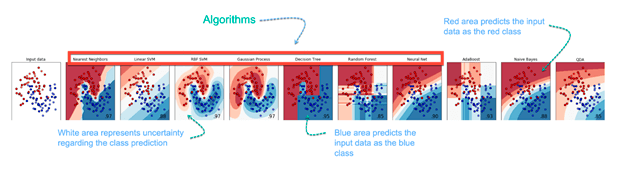
En el siguiente ejemplo de aprendizaje automático, la tarea es predecir el tipo de flor entre tres variedades. Las predicciones se basan en la longitud y el ancho del pétalo. La imagen muestra los resultados de diez algoritmos diferentes. La imagen en la parte superior izquierda es el conjunto de datos. Los datos se clasifican en tres categorías: rojo, azul claro y azul oscuro. Hay algunas agrupaciones. Por ejemplo, en la segunda imagen, todo lo que está arriba a la izquierda pertenece a la categoría roja, en la parte media hay una mezcla de incertidumbre y azul claro, mientras que la parte inferior corresponde a la categoría oscura. Las otras imágenes muestran diferentes algoritmos y cómo intentan clasificar los datos.
Desafíos y limitaciones del aprendizaje automático
Ahora, en este tutorial de aprendizaje automático, aprenderemos sobre las limitaciones del aprendizaje automático:
El principal desafío del aprendizaje automático es la falta de datos o la diversidad en el conjunto de datos. Una máquina no puede aprender si no hay datos disponibles. Además, un conjunto de datos con falta de diversidad puede llevar a que la máquina tenga dificultades para aprender patrones significativos. Es poco probable que un algoritmo pueda extraer información cuando hay poca o ninguna variación en los datos. Se recomienda tener al menos 20 observaciones por grupo para ayudar a la máquina a aprender patrones significativos. Esta restricción puede conducir a una mala evaluación y predicción. Por lo tanto, es importante tener suficientes datos de alta calidad y variados para que el aprendizaje automático funcione de manera efectiva. Además, otro desafío importante del aprendizaje automático es el sesgo en los datos y el modelado, que puede llevar a resultados imprecisos o injustos. Es importante tener en cuenta estos desafíos y trabajar para mitigarlos en el proceso de aprendizaje automático.
Mira Tambien Aprendizaje Automático Supervisado: Concepto, Algoritmos y Ejemplos
Aprendizaje Automático Supervisado: Concepto, Algoritmos y EjemplosAplicaciones del Aprendizaje Automático
En este tutorial de Aprendizaje Automático, exploraremos algunas de las aplicaciones más comunes de esta tecnología:
Aumento:
El Aprendizaje Automático ayuda a los seres humanos en sus tareas diarias, tanto personales como comerciales, sin tener un control total sobre la salida. Esta tecnología se utiliza de diferentes maneras, como en asistentes virtuales, análisis de datos y soluciones de software. El objetivo principal es reducir los errores debidos al sesgo humano.
Automatización:
El Aprendizaje Automático funciona de forma totalmente autónoma en cualquier ámbito sin necesidad de intervención humana. Por ejemplo, los robots pueden realizar los pasos esenciales del proceso en las plantas de fabricación.
Industria Financiera:
El Aprendizaje Automático está ganando popularidad en la industria financiera. Los bancos principalmente utilizan esta tecnología para encontrar patrones dentro de los datos y prevenir el fraude.
Organizaciones Gubernamentales:
Los gobiernos hacen uso del Aprendizaje Automático para gestionar la seguridad pública y los servicios públicos. Un ejemplo es el reconocimiento facial masivo en China, donde el gobierno utiliza la inteligencia artificial para prevenir accidentes peatonales.
Industria de la Salud:
El cuidado de la salud fue una de las primeras industrias en utilizar el Aprendizaje Automático, especialmente para la detección de imágenes médicas.
Marketing:
Se hace un amplio uso de la Inteligencia Artificial en marketing gracias al abundante acceso a los datos. Antes de la era de los datos masivos, los investigadores desarrollaron herramientas matemáticas avanzadas como el análisis bayesiano para estimar el valor de un cliente. Con el auge de los datos, los departamentos de marketing confían en el Aprendizaje Automático para optimizar la relación con el cliente y la campaña de marketing.
Ejemplo de aplicación de Machine Learning en Supply Chain
El aprendizaje automático ofrece resultados excelentes para el reconocimiento visual de patrones, lo que abre muchas aplicaciones potenciales en la inspección física y el mantenimiento en toda la red de la cadena de suministro.
El aprendizaje no supervisado puede buscar patrones comparables en el diverso conjunto de datos de forma rápida. A su vez, la máquina puede realizar inspecciones de calidad en todo el centro logístico, envíos con daños y desgaste.
Mira Tambien Aprendizaje Automático No Supervisado: Algoritmos, Tipos con Ejemplo
Aprendizaje Automático No Supervisado: Algoritmos, Tipos con EjemploUn ejemplo de esto es la plataforma Watson de IBM, que puede determinar el daño del contenedor de envío. Watson combina datos visuales y basados en sistemas para rastrear, informar y hacer recomendaciones en tiempo real.
El año pasado, el administrador de existencias se basó en gran medida en el método principal para evaluar y pronosticar el inventario. Al combinar big data y aprendizaje automático, se han implementado mejores técnicas de pronóstico, lo que ha mejorado en un 20-30% en comparación con las herramientas de pronóstico tradicionales. En términos de ventas, esto se traduce en un aumento del 2 al 3% debido a la potencial reducción en los costos de inventario.
Ejemplo de aplicación de Machine Learning en Google Car
Un ejemplo de aplicación impresionante de Machine Learning es el coche autónomo de Google. El vehículo está equipado con múltiples sensores, como láseres en el techo y un radar en la parte delantera, que le proporcionan datos detallados sobre su entorno. El coche utiliza técnicas de Machine Learning para procesar y analizar toda esta información y así tomar decisiones informadas sobre la conducción.
Además, el coche también utiliza algoritmos de aprendizaje automático para predecir el comportamiento de otros conductores y peatones en la carretera. Por ejemplo, el coche puede analizar la velocidad y el movimiento de otros vehículos para predecir su comportamiento futuro y tomar medidas preventivas.
Lo impresionante es que el coche de Google procesa casi un gigabyte por segundo de datos para tomar estas decisiones en tiempo real. Todo esto demuestra el potencial del Machine Learning en la creación de vehículos autónomos seguros y eficientes en el futuro.
¿Por qué es importante el aprendizaje automático?
El aprendizaje automático es una herramienta crucial para analizar, comprender e identificar patrones en los datos. Una de las principales ideas detrás del aprendizaje automático es que la computadora puede ser entrenada para automatizar tareas que serían exhaustivas o incluso imposibles para un ser humano. La gran ventaja del análisis de datos mediante aprendizaje automático es que este puede tomar decisiones con una intervención humana mínima.
Tomemos el siguiente ejemplo para ilustrar el poder del aprendizaje automático. Un agente minorista podría estimar el precio de una casa en base a su propia experiencia y conocimiento del mercado. Sin embargo, una máquina puede ser entrenada para traducir el conocimiento de un experto en características específicas, como el tamaño de la casa, el barrio, el entorno económico, etc., que influyen en el precio. Para el experto, probablemente le tomó años de experiencia dominar el arte de estimar el precio de una casa y seguir mejorando con cada venta.
Para la máquina, en cambio, se necesitan millones de datos (es decir, ejemplos) para dominar este arte. Al comienzo del aprendizaje, la máquina cometerá errores, de alguna manera como un vendedor junior. Sin embargo, una vez que la máquina vea suficientes ejemplos, tendrá suficiente conocimiento para hacer su estimación con una precisión increíble. Además, la máquina puede ajustar su error de manera eficiente y efectiva.
La mayoría de las grandes empresas han comprendido el valor del aprendizaje automático y la importancia de retener datos. McKinsey ha estimado que el valor de la analítica de datos oscila entre 9,5 y 15,4 billones de dólares, mientras que entre 5 y 7 billones de dólares se pueden atribuir a las técnicas de IA más avanzadas.
Leccione Anteriores —————
1 ) ¿Qué es la inteligencia artificial? Introducción, historia y tipos de IA
2) ¿Qué es el sistema experto en IA? Aprende con ejemplos.
SIGUIENTES LECCIONES:
LECCION 4) Matriz de Confusión en el Aprendizaje Automático: Aprende con Ejemplos
Mira Tambien «La Inteligencia Artificial en la Vida Cotidiana: 13 Casos de Uso»
«La Inteligencia Artificial en la Vida Cotidiana: 13 Casos de Uso»