«Matriz de confusión: una herramienta para medir el rendimiento de clasificación del aprendizaje automático»
¿Qué es la matriz de confusión?
La matriz de confusión es una herramienta muy útil para medir el rendimiento de los modelos de clasificación en el aprendizaje automático. Es una tabla que permite evaluar la precisión del modelo al comparar las predicciones con los valores reales.
A través de la matriz de confusión se pueden identificar los verdaderos positivos, verdaderos negativos, falsos positivos y falsos negativos, lo que permite calcular diferentes métricas de rendimiento, como la precisión, el recall y la F1-score.
En resumen, la matriz de confusión es una herramienta fundamental para medir el rendimiento de los modelos de clasificación en el aprendizaje automático, lo que la convierte en una herramienta clave en el proceso de modelado.
En Este Tutorial Aprenderás
 Aprendizaje Automático Supervisado: Concepto, Algoritmos y Ejemplos
Aprendizaje Automático Supervisado: Concepto, Algoritmos y Ejemplos- ¿Qué es la matriz de confusión?
- Cuatro resultados de la matriz de confusión
- Ejemplo de matriz de confusión
- Cómo calcular una matriz de confusión
- Otros términos importantes usando una matriz de confusión
- ¿Por qué necesita matriz de confusión?
Cuatro resultados de la matriz de confusión
El texto se ve bien, aunque es muy breve y no brinda información adicional que pueda ayudar a los usuarios a comprender la matriz de confusión. Si deseas agregar más información, podrías considerar expandir el texto con explicaciones sobre los cuatro resultados de la matriz de confusión y cómo se relacionan con la precisión del clasificador. Por ejemplo:
«La matriz de confusión es una herramienta esencial para evaluar la precisión de un clasificador al comparar las clases reales y las predicciones. Esta matriz binaria se compone de cuadrados que representan los cuatro resultados principales: verdaderos positivos, verdaderos negativos, falsos positivos y falsos negativos. Cada uno de estos resultados es importante para evaluar la precisión del clasificador y tomar decisiones informadas sobre cómo mejorar su desempeño.»
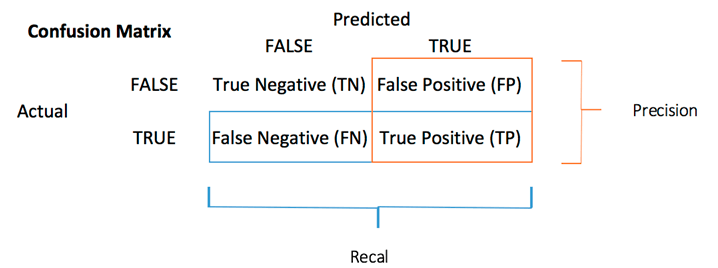
Tabla de confusión
| Valores Reales Positivos | Valores Reales Negativos | |
|---|---|---|
| Valores Predichos Positivos | Verdaderos Positivos (TP) | Falsos Positivos (FP) |
| Valores Predichos Negativos | Falsos Negativos (FN) | Verdaderos Negativos (TN) |
Explicación de la tabla:
- TP (Verdadero Positivo): valores predichos correctamente como positivos reales
- FP (Falso Positivo): valores pronosticados predijeron incorrectamente un positivo real, es decir, valores negativos predichos como positivos
- FN (Falso Negativo): valores positivos predichos como negativos
- TN (Verdadero Negativo): valores predichos correctamente como un negativo real
La precisión del modelo puede ser calculada a partir de los valores en la tabla de confusión.
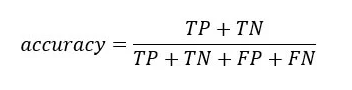
La matriz de confusión es una herramienta útil en el aprendizaje automático que permite medir la recuperación, la precisión, la exactitud y la curva AUC-ROC de un modelo de clasificación. A través de la matriz de confusión, podemos identificar los siguientes términos: Verdadero Positivo, Verdadero Negativo, Falso Positivo y Falso Negativo. Para entender mejor estos términos, se presenta el siguiente ejemplo:
Mira Tambien Aprendizaje Automático No Supervisado: Algoritmos, Tipos con Ejemplo
Aprendizaje Automático No Supervisado: Algoritmos, Tipos con Ejemplo- Verdadero Positivo: cuando el modelo predice correctamente que algo es positivo. Por ejemplo, si se predijo que un equipo ganaría y efectivamente ganó.
- Verdadero Negativo: cuando el modelo predice correctamente que algo es negativo. Por ejemplo, si se predijo que un equipo perdería y efectivamente perdió.
- Falso Positivo: cuando el modelo predice incorrectamente que algo es positivo. Por ejemplo, si se predijo que un equipo ganaría pero en realidad perdió.
- Falso Negativo: cuando el modelo predice incorrectamente que algo es negativo. Por ejemplo, si se predijo que un equipo perdería pero en realidad ganó.
Es importante recordar que estos términos describen los valores predichos como Verdadero o Falso, y Positivo o Negativo. La matriz de confusión nos permite evaluar el rendimiento del modelo y determinar su eficacia en la clasificación de datos.
Cómo calcular una matriz de confusión
Aquí, está el proceso paso a paso para calcular una matriz de confusión en la minería de datos
Paso 1) Primero, debe probar el conjunto de datos con sus valores de resultado esperados.
Paso 2) Prediga todas las filas en el conjunto de datos de prueba.
Paso 3) Calcule las predicciones y los resultados esperados:
Mira Tambien «La Inteligencia Artificial en la Vida Cotidiana: 13 Casos de Uso»
«La Inteligencia Artificial en la Vida Cotidiana: 13 Casos de Uso»El total de predicciones correctas de cada clase. El total de predicciones incorrectas de cada clase. Después de eso, estos números se organizan en los siguientes métodos:
Cada fila de la matriz se vincula a una clase predicha. Cada columna de la matriz se corresponde con una clase real. Los recuentos totales de clasificación correcta e incorrecta se ingresan en la tabla. La suma de las predicciones correctas para una clase entra en la columna prevista y la fila esperada para ese valor de clase. La suma de predicciones incorrectas para una clase va a la fila esperada para ese valor de clase y la columna pronosticada para ese valor de clase específico.
Otros términos importantes relacionados con el uso de la matriz de confusión son los siguientes:
- Valor predictivo positivo (PVV): es una métrica muy similar a la precisión, pero tiene en cuenta la prevalencia de las clases. Si las clases están perfectamente equilibradas, el PVV será igual a la precisión.
- Tasa de error nulo: esta métrica define cuántas veces tu modelo predice incorrectamente si solo predice la clase mayoritaria. Sirve como una métrica de referencia para comparar tu clasificador.
- Puntuación F: la puntuación F1 es una métrica que combina tanto la recuperación (verdaderos positivos) como la precisión. Se trata de una media ponderada que se utiliza para evaluar la precisión del modelo.
- Curva ROC: la curva ROC muestra la tasa de verdaderos positivos frente a la tasa de falsos positivos en varios puntos de corte. También muestra la compensación entre la sensibilidad (tasa de verdaderos positivos) y la especificidad (tasa de verdaderos negativos).
- Precisión: la métrica de precisión se refiere a la exactitud de la clase positiva. Mide la probabilidad de que la predicción de la clase positiva sea correcta.
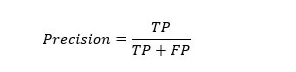
La puntuación máxima que se puede obtener es 1, lo que indica que el clasificador ha clasificado correctamente todos los valores positivos. Sin embargo, la precisión por sí sola no proporciona una imagen completa del rendimiento del clasificador, ya que ignora la clase negativa. Por lo tanto, se suele combinar con la métrica de recuperación, también conocida como sensibilidad o tasa de verdaderos positivos.
Sensibilidad : LA SENSIBILIDAD mide la proporción de clases positivas detectadas correctamente, lo que indica la habilidad del modelo para reconocer correctamente una clase positiva.
Mira Tambien Aprendizaje Profundo vs Aprendizaje Automático : ¿Cuál es la Diferencia?
Aprendizaje Profundo vs Aprendizaje Automático : ¿Cuál es la Diferencia?
¿Por qué necesita matriz de confusión?
Estos son los pros/beneficios de usar una matriz de confusión.
- Muestra cómo cualquier modelo de clasificación se confunde cuando hace predicciones.
- La matriz de confusión no solo le brinda información sobre los errores que comete su clasificador, sino también sobre los tipos de errores que se cometen.
- Este desglose lo ayuda a superar la limitación de usar solo la precisión de la clasificación.
- Cada columna de la matriz de confusión representa las instancias de esa clase predicha.
- Cada fila de la matriz de confusión representa las instancias de la clase real.
- Proporciona información no solo sobre los errores que comete un clasificador, sino también sobre los errores que se están cometiendo.
LECCIONES ANTERIORES: