¿Qué es el aprendizaje profundo?
Deep Learning es un software de computadora que imita la red de neuronas en un cerebro. Es un subconjunto del aprendizaje automático basado en redes neuronales artificiales con aprendizaje de representación. Se llama aprendizaje profundo porque hace uso de redes neuronales profundas. Este aprendizaje puede ser supervisado, semi-supervisado o no supervisado. Los algoritmos de aprendizaje profundo se construyen con capas conectadas.
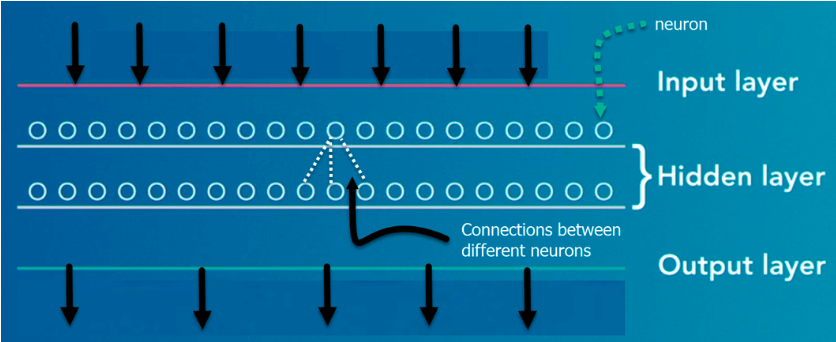
La primera capa se llama la capa de entrada
La última capa se llama Capa de salida.
Todas las capas intermedias se denominan Capas ocultas. La palabra profunda significa que la red une las neuronas en más de dos capas.
EN DECIR
- Deep Learning es un tipo de software de computadora que simula la red de neuronas en un cerebro.
- Es un subconjunto del aprendizaje automático que utiliza redes neuronales artificiales con aprendizaje de representación.
- El término «profundo» se refiere a que se utilizan redes neuronales profundas con múltiples capas ocultas.
- Los algoritmos de aprendizaje profundo se construyen con capas conectadas, incluyendo la capa de entrada y la capa de salida.
- Las capas intermedias se denominan capas ocultas.
- El aprendizaje profundo puede ser supervisado, semi-supervisado o no supervisado.
| Capa | Función | Descripción |
|---|---|---|
| Entrada | Recepción de datos | La primera capa recibe los datos de entrada, que pueden ser imágenes, texto, audio, entre otros. |
| Capas ocultas | Procesamiento de datos | Las capas ocultas son las capas intermedias entre la capa de entrada y la de salida. Cada capa procesa los datos recibidos de la capa anterior y los transforma antes de pasarlos a la siguiente capa. |
| Salida | Generación de resultados | La capa de salida es la última capa y genera los resultados de la red. Dependiendo del problema que se esté resolviendo, la capa de salida puede tener una o varias neuronas. |
| Pesos y bias | Ajuste de parámetros | Los pesos y bias son parámetros que la red ajusta durante el entrenamiento para mejorar su desempeño. Estos parámetros se utilizan para calcular la salida de cada neurona en cada capa. |
| Función de activación | Introducción de no linealidad | La función de activación se aplica a la salida de cada neurona para introducir no linealidad en la red. Esto permite que la red sea más expresiva y pueda modelar problemas más complejos. |
Cada capa Oculta está compuesta de neuronas. Las neuronas están conectadas entre sí. La neurona procesará y luego propagará la señal de entrada que recibe a la capa superior. La fuerza de la señal dada a la neurona en la siguiente capa depende del peso, el sesgo y la función de activación. La red consume grandes cantidades de datos de entrada y los opera a través de múltiples capas; la red puede aprender características cada vez más complejas de los datos en cada capa. En este tutorial de aprendizaje profundo para principiantes, aprenderá conceptos básicos de aprendizaje profundo como:

PROCESO DE APRENDISAJE PROFUNDO
El proceso de aprendizaje profundo se puede entender a través de una analogía con un bebé que aprende a reconocer objetos. El bebé señala objetos con su dedo y dice «gato», mientras que sus padres lo corrigen si se equivoca. Con el tiempo, el bebé aprende a reconocer características más complejas del gato, como la forma de su cuerpo o su patrón de pelaje, y mejora su capacidad para identificar correctamente a los gatos.
Una red neuronal profunda funciona de manera similar. Cada capa representa un nivel más profundo de conocimiento, lo que permite a la red aprender características más complejas. El proceso de aprendizaje ocurre en dos fases: la primera fase implica la aplicación de una transformación no lineal a los datos de entrada, y la segunda fase tiene como objetivo mejorar el modelo utilizando un método matemático conocido como derivada.
La red neuronal se entrena mediante la repetición de estas dos fases cientos o miles de veces, hasta que se alcanza un nivel aceptable de precisión. Este proceso de repetición se llama iteración.
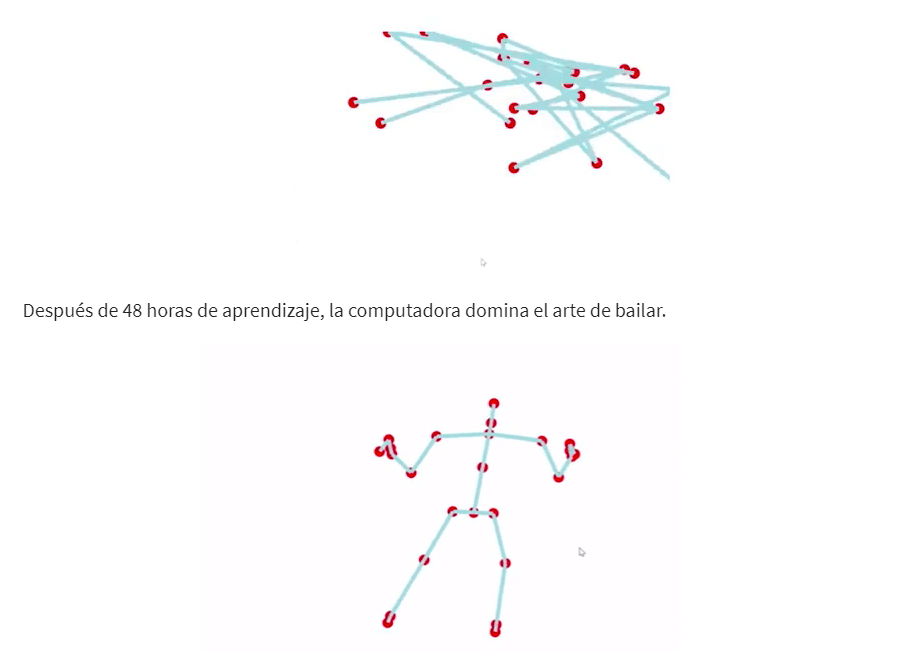
Un ejemplo de aprendizaje profundo puede ser la enseñanza de una computadora a bailar. Al principio, después de solo 10 minutos de entrenamiento, la computadora no sabe bailar y parece torpe. Sin embargo, después de 48 horas de entrenamiento, la computadora domina el arte del baile y puede hacer movimientos complejos con facilidad.
Clasificación de Redes Neuronales
En el mundo del aprendizaje profundo, existen dos tipos de redes neuronales: las redes neuronales superficiales y las redes neuronales profundas. Las redes neuronales superficiales tienen solo una capa oculta entre la entrada y la salida, mientras que las redes neuronales profundas tienen más de una capa. Un ejemplo de red neuronal profunda es el modelo Google LeNet para el reconocimiento de imágenes, que cuenta con 22 capas.
Tipos de Redes de Aprendizaje Profundo
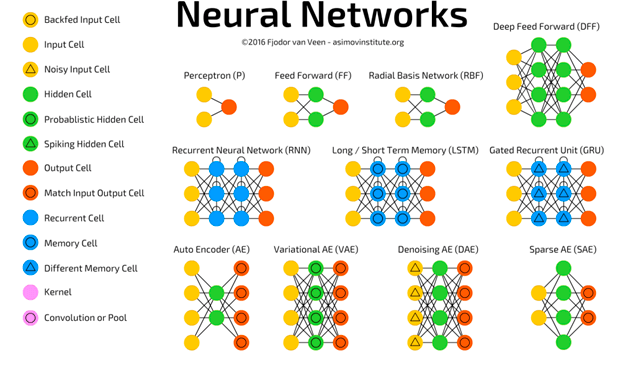
Además de la clasificación anterior, existen varios tipos de redes de aprendizaje profundo. Los dos principales son:
- Redes Neuronales de Avance: Este tipo de red neuronal artificial es el más simple. La información fluye en una sola dirección, desde la capa de entrada, pasando por las capas ocultas y terminando en la capa de salida. No hay bucles y la información se detiene en las capas de salida.
- Redes Neuronales Recurrentes (RNN): Las RNN son una red neuronal de varias capas que pueden almacenar información en nodos de contexto, lo que les permite aprender secuencias de datos y generar otra secuencia. En otras palabras, son redes neuronales artificiales cuyas conexiones entre neuronas incluyen bucles. Son muy adecuados para procesar secuencias de entradas.

En la actualidad, el aprendizaje profundo se utiliza en muchas áreas, como la conducción autónoma, los teléfonos móviles, el motor de búsqueda de Google, la detección de fraudes y la televisión, entre otros.
Mira Tambien Red Neuronal de Retropropagación: Cómo Funciona el Algoritmo de Retropropagación
Red Neuronal de Retropropagación: Cómo Funciona el Algoritmo de RetropropagaciónRedes neuronales recurrentes
Por ejemplo, si la tarea es predecir la siguiente palabra en la oración “¿Quieres un…………?
Las neuronas RNN recibirán una señal que apuntará al inicio de la oración.
La red recibe la palabra «Do» como entrada y produce un vector del número.
Este vector se retroalimenta a la neurona para proporcionar una memoria a la red.
Esta etapa ayuda a la cadena a recordar que recibió “Do” y lo recibió en primera posición.
La red procederá de manera similar a las siguientes palabras. Toma la palabra «usted» y «quiero».
El estado de las neuronas se actualiza al recibir cada palabra.
La etapa final ocurre después de recibir la palabra «a». La red neuronal proporcionará una probabilidad para cada palabra en inglés que se puede usar para completar la oración. Un RNN bien entrenado probablemente asigna una alta probabilidad a «café», «bebida», «hamburguesa», etc.
Usos comunes de RNN
Ayudar a los comerciantes de valores a generar informes analíticos
Detectar anormalidades en el contrato de estado financiero
Detectar transacciones fraudulentas con tarjeta de crédito
Proporcione un título para las imágenes.
Mira Tambien Aprendizaje por Refuerzo: Algoritmos, Tipos y Ejemplos
Aprendizaje por Refuerzo: Algoritmos, Tipos y EjemplosChatbots potentes
Los usos estándar de RNN ocurren cuando los profesionales están trabajando con secuencias o datos de series de tiempo (por ejemplo, grabaciones de audio o texto).
Redes neuronales convolucionales (CNN)
CNN es una red neuronal de múltiples capas con una arquitectura única diseñada para extraer características cada vez más complejas de los datos en cada capa para determinar la salida. Las CNN son adecuadas para tareas de percepción.
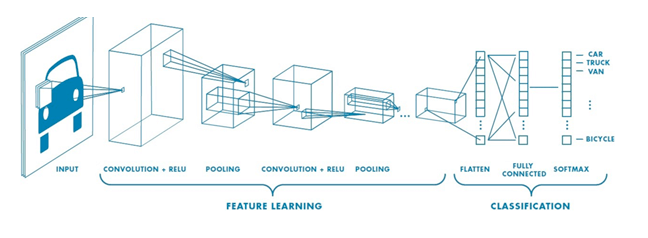
Red neuronal convolucional
CNN se usa principalmente cuando hay un conjunto de datos no estructurados (p. ej., imágenes) y los profesionales necesitan extraer información de ellos.
Por ejemplo, si la tarea es predecir una leyenda de imagen:
- La CNN recibe una imagen de digamos un gato, esta imagen, en términos informáticos, es una colección del píxel. Generalmente, una capa para la imagen en escala de grises y tres capas para una imagen en color.
- Durante el aprendizaje de características (es decir, capas ocultas), la red identificará características únicas, por ejemplo, la cola del gato, la oreja, etc.
- Cuando la red aprendió a fondo cómo reconocer una imagen, puede proporcionar una probabilidad para cada imagen que conoce. La etiqueta con mayor probabilidad se convertirá en la predicción de la red.
Aprendizaje reforzado
El aprendizaje por refuerzo es una rama del aprendizaje automático que consiste en entrenar sistemas mediante la recepción de «recompensas» o «castigos» virtuales, permitiéndoles aprender por prueba y error. Uno de los hitos más destacados del aprendizaje por refuerzo fue cuando DeepMind, de Google, utilizó esta técnica para vencer a un campeón humano en el juego de Go. Además, el aprendizaje por refuerzo se utiliza en videojuegos para mejorar la experiencia de juego, proporcionando bots más inteligentes.
Entre los algoritmos más populares utilizados en el aprendizaje por refuerzo se encuentran:
- Q-Aprendizaje
- Red Q Profunda
- Estado-Acción-Recompensa-Estado-Acción (SARSA)
- Gradiente de Política Determinista Profundo (DDPG)
El Q-Aprendizaje es un algoritmo utilizado para determinar la mejor acción a tomar en función del estado actual. La Red Q Profunda utiliza una red neuronal para aproximar la función Q, que representa el valor esperado de tomar una acción en un estado determinado. El SARSA es un algoritmo similar al Q-Aprendizaje, pero se utiliza para entornos donde el agente no tiene conocimiento completo de su entorno. Finalmente, el DDPG se utiliza para resolver problemas de control continuo, donde se busca encontrar una política determinista óptima que permita al agente aprender la mejor acción a tomar en función de su estado actual.
Ejemplos de aplicaciones de aprendizaje profundo
Ahora, en este tutorial de aprendizaje profundo para principiantes, aprendamos sobre las aplicaciones de aprendizaje profundo:
IA en finanzas:
- El sector de la tecnología financiera ya ha comenzado a utilizar la IA para ahorrar tiempo, reducir costos y agregar valor. El aprendizaje profundo está cambiando la industria de los préstamos mediante el uso de una calificación crediticia más sólida. Los responsables de la toma de decisiones crediticias pueden utilizar la IA para aplicaciones sólidas de préstamos crediticios para lograr una evaluación de riesgos más rápida y precisa, utilizando inteligencia artificial para tener en cuenta el carácter y la capacidad de los solicitantes. Underwrite es una empresa Fintech que ofrece una solución de inteligencia artificial para empresas de creación de crédito. underwrite.ai utiliza IA para detectar qué solicitante tiene más probabilidades de devolver un préstamo. Su enfoque supera radicalmente a los métodos tradicionales.
IA en RRHH:
- Under Armour, una empresa de ropa deportiva revoluciona la contratación y moderniza la experiencia de los candidatos con la ayuda de la IA. De hecho, Under Armour reduce el tiempo de contratación de sus tiendas minoristas en un 35 %. Under Armour enfrentó un creciente interés de popularidad en 2012. Tenían, en promedio, 30000 currículums por mes. Leer todas esas solicitudes y comenzar el proceso de selección y entrevista tomó demasiado tiempo. El largo proceso para contratar e incorporar a las personas afectó la capacidad de Under Armour de tener sus tiendas minoristas con todo el personal, ampliadas y listas para operar. En ese momento, Under Armour tenía toda la tecnología de RR. Under armour elige HireVue , un proveedor de inteligencia artificial para soluciones de recursos humanos, tanto para entrevistas bajo demanda como en vivo. Los resultados fueron un farol; lograron disminuir en un 35% el tiempo de llenado. A cambio, el personal contratado de mayor calidad.
IA en marketing:
- La IA es una herramienta valiosa para la gestión del servicio al cliente y los desafíos de personalización. El reconocimiento de voz mejorado en la gestión del centro de llamadas y el enrutamiento de llamadas como resultado de la aplicación de técnicas de inteligencia artificial permite una experiencia más fluida para los clientes. Por ejemplo, el análisis de aprendizaje profundo del audio permite que los sistemas evalúen el tono emocional de un cliente. Si el cliente responde mal al chatbot de IA, el sistema puede redirigir la conversación a operadores humanos reales que se hagan cargo del problema.
Además de los tres ejemplos de aprendizaje profundo anteriores, la IA se usa ampliamente en otros sectores/industrias.
¿Por qué es importante el aprendizaje profundo?
El aprendizaje profundo es una herramienta esencial en la actualidad, ya que permite convertir las predicciones en resultados tangibles y procesables. Su capacidad para descubrir patrones y realizar predicciones basadas en el conocimiento lo convierte en una herramienta poderosa en diversas industrias. Además, cuando se combina con Big Data, el aprendizaje profundo puede producir resultados sin precedentes en términos de productividad, ventas, gestión e innovación.
En comparación con los métodos tradicionales, el aprendizaje profundo se destaca en la precisión de sus algoritmos. Por ejemplo, en la clasificación de imágenes, los algoritmos de aprendizaje profundo son un 41 % más precisos que los algoritmos de aprendizaje automático. En el reconocimiento facial, los algoritmos de aprendizaje profundo son un 27 % más precisos, y en el reconocimiento de voz, son un 25 % más precisos. Estas ventajas hacen que el aprendizaje profundo sea cada vez más importante en una amplia gama de aplicaciones en la actualidad.
Mira Tambien Tutorial de Lógica Difusa: Arquitectura, Aplicación, Ejemplo
Tutorial de Lógica Difusa: Arquitectura, Aplicación, EjemploLimitaciones del aprendizaje profundo
Ahora, en este tutorial de redes neuronales, aprenderemos sobre las limitaciones del aprendizaje profundo: como ves al texto que puedes mejorar
- Necesidad de grandes cantidades de datos: el aprendizaje profundo requiere de grandes conjuntos de datos para funcionar de manera óptima. Esto puede ser una limitación para organizaciones que no cuentan con los recursos o la cantidad suficiente de datos.
- Requiere un alto poder de procesamiento: los algoritmos de aprendizaje profundo son complejos y requieren de una gran cantidad de recursos de computación. Esto puede ser una limitación para organizaciones con infraestructura limitada o costos de hardware elevados.
- El aprendizaje profundo puede ser opaco: la complejidad de los algoritmos de aprendizaje profundo puede hacer que los resultados sean difíciles de interpretar. Esto puede ser un problema en áreas como la medicina o la justicia, donde se necesitan explicaciones claras y concisas de los resultados.
- Vulnerabilidad a los datos de entrenamiento: el aprendizaje profundo puede verse afectado por datos de entrenamiento sesgados o no representativos. Esto puede llevar a resultados erróneos o prejuicios involuntarios.
Es importante tener en cuenta estas limitaciones al implementar el aprendizaje profundo en una organización. Si se manejan adecuadamente, estas limitaciones no deben ser un obstáculo para aprovechar al máximo el potencial del aprendizaje profundo.
Etiquetado de datos
El etiquetado de datos es una tarea importante y propensa a errores en el proceso de entrenamiento de modelos de IA basados en aprendizaje supervisado. En este proceso, los humanos deben categorizar y etiquetar los datos subyacentes para que el modelo pueda aprender a partir de ellos. Por ejemplo, las empresas que desarrollan tecnologías de vehículos autónomos a menudo contratan a cientos de personas para anotar manualmente horas de transmisiones de video de prototipos de vehículos, con el fin de entrenar a los sistemas de IA que impulsan estos vehículos. Aunque es un proceso laborioso, el etiquetado de datos es crucial para garantizar la precisión y la confiabilidad de los modelos de IA.
Obtener grandes conjuntos de datos de entrenamiento
Se ha demostrado que técnicas simples de aprendizaje profundo como CNN pueden imitar el conocimiento de expertos en medicina y otros campos en algunos casos. Sin embargo, la actual tendencia de aprendizaje automático requiere conjuntos de datos de entrenamiento que no solo estén etiquetados, sino que también sean lo suficientemente amplios y universales.
Los métodos de aprendizaje profundo requieren miles de observaciones para que los modelos tengan un buen desempeño en las tareas de clasificación y, en algunos casos, millones para que alcancen el nivel de rendimiento humano. No es sorprendente que las grandes empresas tecnológicas sean famosas por su uso del aprendizaje profundo, aprovechando big data para acumular petabytes de datos y crear modelos de aprendizaje profundo impresionantes y altamente precisos.
Explicar un problema
La complejidad de los modelos de IA a menudo dificulta su explicación en términos comprensibles para los humanos, especialmente cuando se trata de entender por qué se ha tomado una determinada decisión. Este factor ha obstaculizado la adopción de algunas herramientas de IA en áreas donde la interpretación es esencial o altamente valorada.
Además, a medida que la IA se aplica en un rango cada vez más amplio de situaciones, es probable que surjan requisitos normativos que exijan la explicabilidad de los modelos de IA, lo que podría impulsar la necesidad de desarrollar modelos más transparentes y fáciles de interpretar.
Resumes
El aprendizaje profundo es considerado el nuevo estado del arte en el campo de la inteligencia artificial. La arquitectura de aprendizaje profundo está compuesta por una capa de entrada, capas ocultas y una capa de salida. La palabra «profundo» hace referencia a que hay más de dos capas completamente conectadas.
Existen diversas redes neuronales diseñadas para realizar tareas específicas, como por ejemplo la CNN para trabajar con imágenes y la RNN para analizar series de tiempo y textos.
Actualmente, el aprendizaje profundo está siendo utilizado en distintos campos, como finanzas, marketing y cadena de suministro. Las grandes empresas son las primeras en adoptar esta tecnología debido a la gran cantidad de datos con los que ya cuentan. No obstante, el aprendizaje profundo requiere de conjuntos de datos extensos y etiquetados para su entrenamiento.
Lecciones Anteriores:
- LECCION 1) ¿Qué es la Inteligencia Artificial? Introducción, Historia y Tipos de IA
- LECCION 2) Sistema Experto en IA: Aprende con Ejemplos
- LECCION 3) Aprendizaje Automático para Principiantes: Conceptos Básicos de ML
- LECCION 4) Matriz de Confusión en el Aprendizaje Automático: Aprende con Ejemplos
Siguiente Leccion:
LECCION 6 ) Aprendizaje Automático Supervisado: Algoritmos con Ejemplos
Mira Tambien ¿Qué es la ciencia de datos? Introducción, conceptos básicos y proceso
¿Qué es la ciencia de datos? Introducción, conceptos básicos y proceso