¿Qué es el Aprendizaje Automático Supervisado?
El Aprendizaje Automático Supervisado es un algoritmo que utiliza datos de entrenamiento etiquetados para predecir resultados en datos no vistos previamente. En este enfoque, se entrena a la máquina utilizando datos que están previamente «etiquetados» con respuestas correctas. Podemos compararlo con el aprendizaje en presencia de un supervisor o maestro.
La construcción, escalado e implementación exitosa de modelos precisos de Aprendizaje Automático Supervisado requiere tiempo y experiencia técnica de un equipo altamente calificado de científicos de datos. Además, estos científicos de datos deben estar preparados para ajustar y mejorar continuamente los modelos para asegurarse de que sigan siendo válidos incluso a medida que cambien los datos.
En este tutorial, exploraremos los siguientes aspectos:
- ¿Qué es el Aprendizaje Automático Supervisado?
- Cómo funciona el aprendizaje supervisado.
- Tipos de algoritmos utilizados en el Aprendizaje Automático Supervisado.
- Técnicas tanto supervisadas como no supervisadas en el Aprendizaje Automático.
- Desafíos asociados al Aprendizaje Automático Supervisado.
- Ventajas y desventajas del aprendizaje supervisado.
- Mejores prácticas para implementar el Aprendizaje Automático Supervisado.
El aprendizaje supervisado en el aprendizaje automático se basa en el uso de conjuntos de datos de entrenamiento para lograr los resultados deseados. Estos conjuntos de datos contienen tanto las entradas como las salidas correctas, lo que ayuda al modelo a aprender de manera más efectiva. Para ilustrar esto, consideremos el ejemplo de entrenar una máquina para predecir el tiempo de viaje desde el lugar de trabajo hasta el hogar.
Mira Tambien Aprendizaje Automático No Supervisado: Algoritmos, Tipos con Ejemplo
Aprendizaje Automático No Supervisado: Algoritmos, Tipos con EjemploComienza creando un conjunto de datos etiquetados que incluye información relevante, como:
- Condiciones climáticas.
- Hora del día.
- Días festivos.
Estos detalles representan los inputs en este ejemplo de aprendizaje supervisado, mientras que la salida esperada es la cantidad de tiempo que se tardó en conducir desde el lugar de trabajo hasta el hogar en un día específico.
Instintivamente, sabemos que si está lloviendo, tomará más tiempo llegar a casa. Sin embargo, la máquina necesita datos y estadísticas para establecer estas relaciones. Es por eso que desarrollar un modelo de aprendizaje supervisado se vuelve crucial.
Veamos algunos ejemplos de cómo desarrollar un modelo de aprendizaje supervisado utilizando este ejemplo. Lo primero que necesitas es crear un conjunto de entrenamiento. Este conjunto incluirá el tiempo total de viaje y los factores correspondientes, como el clima y el horario. A partir de este conjunto de entrenamiento, la máquina puede observar una relación directa entre la cantidad de lluvia y el tiempo requerido para llegar a casa.
Por lo tanto, puede determinar que a mayor cantidad de lluvia, más tiempo tomará llegar a casa. También puede identificar la conexión entre la hora de salida del trabajo y el tiempo de viaje.
Mira Tambien «La Inteligencia Artificial en la Vida Cotidiana: 13 Casos de Uso»
«La Inteligencia Artificial en la Vida Cotidiana: 13 Casos de Uso»Cuanto más cerca estés de las 6 p.m., más tiempo tomará llegar a casa. Tu máquina puede descubrir algunas de estas relaciones mediante el análisis de los datos etiquetados.
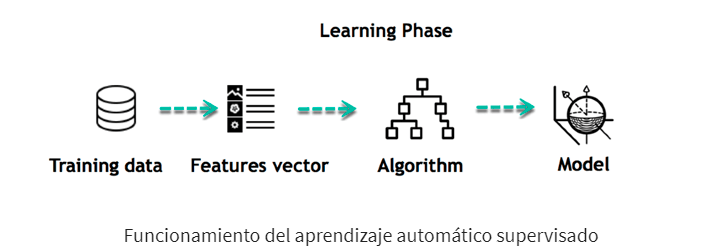
Este es el inicio de tu modelo de datos, donde comienza a comprender cómo la lluvia afecta la forma en que las personas conducen. También empiezas a notar que más personas viajan durante un momento particular del día.
Aquí tienes una versión mejorada del segmento sobre los tipos de algoritmos de aprendizaje automático supervisado:
Existen diferentes tipos de algoritmos de aprendizaje automático supervisado, entre los cuales se incluyen:
- Regresión: La regresión es una técnica que predice un único valor de salida utilizando datos de entrenamiento. Por ejemplo, se puede utilizar la regresión para predecir el precio de una vivienda basándose en variables como la ubicación y el tamaño de la casa.
- Puntos fuertes: Las salidas tienen una interpretación probabilística y el algoritmo se puede regularizar para evitar el sobreajuste.
- Debilidades: Puede tener un rendimiento inferior cuando hay límites de decisión múltiples o no lineales, y no captura relaciones más complejas.
Regresión logística:
- Regresión logística: La regresión logística es un método utilizado para estimar valores discretos basados en un conjunto de variables independientes. Ayuda a predecir la probabilidad de ocurrencia de un evento ajustando los datos a una función logit. Se utiliza tanto para clasificación binaria como multiclase.
- Clasificación: La clasificación implica agrupar la salida en clases. Cuando el algoritmo intenta etiquetar la entrada en dos clases distintas, se llama clasificación binaria, mientras que la selección entre más de dos clases se conoce como clasificación multiclase. Por ejemplo, se puede utilizar la clasificación para determinar si alguien será o no moroso en un préstamo.
- Puntos fuertes: Los árboles de clasificación funcionan bien en la práctica.
- Debilidades: Los árboles individuales sin restricciones pueden sobreajustarse.
Algunos ejemplos de algoritmos de clasificación son:
Clasificadores Naive Bayes:
- Clasificadores Naive Bayes: Este modelo es fácil de construir y es útil para grandes conjuntos de datos. Se basa en gráficos acíclicos dirigidos que asumen independencia entre los nodos secundarios y su padre.
- Árboles de decisión: Clasifican las instancias ordenándolas según el valor de una característica. Cada nodo representa una característica y cada rama representa un valor que el nodo puede asumir. Los árboles de decisión son ampliamente utilizados para la clasificación.
- Máquinas de vectores de soporte (SVM): Son algoritmos de aprendizaje desarrollados en la década de 1990. Se basan en la teoría del aprendizaje estadístico y utilizan funciones de kernel. Las SVM se aplican en diversos campos, como recuperación de información multimedia, bioinformática y reconocimiento de patrones.
Técnicas de aprendizaje automático supervisadas y no supervisadas
| Residencia en | Técnica de aprendizaje automático supervisado | Técnica de aprendizaje automático no supervisado |
|---|---|---|
| Datos de entrada | Los algoritmos se entrenan utilizando datos etiquetados. | Los algoritmos se utilizan contra datos que no están etiquetados. |
| Complejidad computacional | El aprendizaje supervisado es un método más simple. | El aprendizaje no supervisado es computacionalmente complejo. |
| Exactitud | Método altamente preciso y confiable. | Método menos preciso y confiable. |
Desafíos en el aprendizaje automático supervisado:
- Datos de entrenamiento con características irrelevantes: Los datos de entrada que contienen características irrelevantes pueden conducir a resultados inexactos.
- Preparación y preprocesamiento de datos: La manipulación y preparación de los datos de entrenamiento siempre presenta desafíos.
- Precisión con valores inexactos o incompletos: La precisión del modelo puede verse afectada cuando se ingresan valores imposibles, improbables o incompletos como datos de entrenamiento.
- Dependencia de expertos: Si no se cuenta con un experto disponible, puede requerirse un enfoque de «fuerza bruta» para determinar las características adecuadas para entrenar el modelo, lo cual puede resultar en inexactitudes.
Ventajas del aprendizaje supervisado:
- Aprovechamiento de la experiencia previa: El aprendizaje supervisado permite utilizar datos previos o generar salidas basadas en experiencias anteriores.
- Optimización de criterios de rendimiento: Ayuda a optimizar los criterios de rendimiento utilizando la experiencia adquirida.
- Resolución de problemas del mundo real: El aprendizaje automático supervisado es útil para resolver una variedad de problemas computacionales del mundo real.
Desventajas del aprendizaje supervisado:
- Sobreajuste del límite de decisión: El modelo puede sobreentrenarse si el conjunto de entrenamiento no contiene ejemplos representativos de todas las clases.
- Necesidad de ejemplos representativos: Se requiere una selección cuidadosa de ejemplos representativos de cada clase durante el entrenamiento del clasificador.
- Desafíos con big data: Clasificar grandes volúmenes de datos puede ser un desafío en términos de recursos computacionales y eficiencia.
- Requerimientos de tiempo de cálculo: El entrenamiento en aprendizaje supervisado puede llevar mucho tiempo de cálculo.
Mejores prácticas para el aprendizaje supervisado:
- Selección del conjunto de entrenamiento: Decidir qué tipo de datos se utilizarán como conjunto de entrenamiento.
- Estructura de la función aprendida y algoritmo de aprendizaje: Determinar la estructura de la función que se quiere aprender y seleccionar el algoritmo de aprendizaje apropiado.
- Obtención de resultados de expertos humanos o mediciones correspondientes.
resumen:
El aprendizaje supervisado utiliza datos etiquetados para entrenar la máquina.
Mira Tambien Aprendizaje Profundo vs Aprendizaje Automático : ¿Cuál es la Diferencia?
Aprendizaje Profundo vs Aprendizaje Automático : ¿Cuál es la Diferencia?Un ejemplo es predecir el tiempo de viaje desde el trabajo a casa.
Regresión y clasificación son dimensiones clave del aprendizaje supervisado.
Aunque es más simple que el aprendizaje no supervisado, puede enfrentar desafíos cuando las características irrelevantes afectan los resultados.
Sin embargo, su principal ventaja es la capacidad de recopilar datos basados en experiencias previas.
Como desventaja, el límite de decisión puede sobreajustarse si el conjunto de entrenamiento carece de ejemplos relevantes.
Mira Tambien Aprendizaje profundo vs aprendizaje automatico cual es la diferencia
Aprendizaje profundo vs aprendizaje automatico cual es la diferenciaSe recomienda seleccionar cuidadosamente los datos de entrenamiento como práctica óptima.
Lecciones Anteriores:
- LECCION 1) ¿Qué es la Inteligencia Artificial? Introducción, Historia y Tipos de IA
- LECCION 2) Sistema Experto en IA: Aprende con Ejemplos
- LECCION 3) Aprendizaje Automático para Principiantes: Conceptos Básicos de ML
- LECCION 4) Matriz de Confusión en el Aprendizaje Automático: Aprende con Ejemplos
- LECCION 5) Aprendizaje Profundo para Principiantes: Proceso y Tipos
Siguiente Leccion:
LECCION 7) Aprendizaje Automático No Supervisado: Algoritmos, Tipos con Ejemplo