Diferencia clave entre el aprendizaje supervisado y no supervisado
La diferencia clave entre el aprendizaje supervisado y el no supervisado radica en cómo se realiza el entrenamiento de la máquina.
En el aprendizaje supervisado, se entrenan modelos utilizando datos que están debidamente «etiquetados» o clasificados. En cambio, el aprendizaje no supervisado es una técnica de aprendizaje automático en la cual no se requiere supervisar el modelo con datos etiquetados.
El aprendizaje supervisado permite recopilar datos o producir una salida de datos basada en experiencias previas. En contraste, el aprendizaje no supervisado ayuda a encontrar patrones desconocidos en los datos sin la necesidad de contar con información previa.
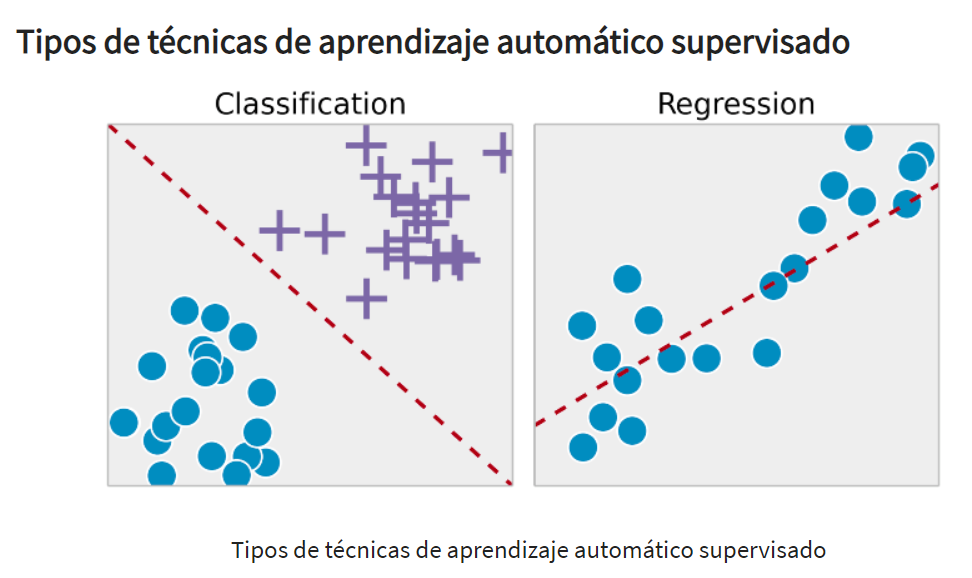
Dentro del aprendizaje supervisado, encontramos dos tipos de técnicas principales: la regresión y la clasificación. La regresión se utiliza para predecir valores continuos, mientras que la clasificación se emplea para asignar elementos a categorías o clases específicas.
Por otro lado, el aprendizaje no supervisado también cuenta con dos técnicas comunes: la agrupación y la asociación. La agrupación se utiliza para identificar grupos o clústeres en los datos, mientras que la asociación busca encontrar relaciones o patrones de co-ocurrencia entre diferentes elementos.
En un modelo de aprendizaje supervisado, se proporcionan tanto las variables de entrada como las de salida para el entrenamiento. Por el contrario, en un modelo de aprendizaje no supervisado, solo se brindan los datos de entrada sin información adicional.
En este tutorial sobre la diferencia entre ambos tipos de aprendizaje automático, aprenderás:
- ¿Qué es el aprendizaje automático supervisado?
- ¿Qué es el aprendizaje no supervisado?
- ¿Por qué se utiliza el aprendizaje supervisado?
- ¿Por qué se utiliza el aprendizaje no supervisado?
- ¿Cómo funciona el aprendizaje supervisado?
- ¿Cómo funciona el aprendizaje no supervisado?
- Tipos de técnicas de aprendizaje automático supervisado
- Tipos de técnicas de aprendizaje automático no supervisado
- Diferencias entre el aprendizaje supervisado y el no supervisado
¿Qué es el aprendizaje automático supervisado?
En el aprendizaje automático supervisado, se entrena a la máquina utilizando datos que están correctamente «etiquetados».
Esto significa que algunos datos ya están etiquetados con la respuesta correcta.
Puede compararse con el aprendizaje que tiene lugar en presencia de un supervisor o maestro.
Un algoritmo de aprendizaje supervisado aprende de los datos de entrenamiento etiquetados y ayuda a predecir los resultados de datos no vistos anteriormente.
Construir, escalar e implementar con éxito un modelo preciso de aprendizaje automático supervisado requiere tiempo y experiencia técnica por parte de un equipo de científicos de datos altamente calificados.
Mira TambienAdemás, el científico de datos debe actualizar los modelos para garantizar que los conocimientos proporcionados sigan siendo válidos a medida que cambian los datos.
¿Qué es el aprendizaje no supervisado?
El aprendizaje no supervisado es una técnica de aprendizaje automático en la que no es necesario supervisar el modelo.
En cambio, se permite que el modelo funcione por sí solo para descubrir información. Se centra principalmente en datos no etiquetados.
Los algoritmos de aprendizaje no supervisado permiten realizar tareas de procesamiento más complejas en comparación con el aprendizaje supervisado.
Sin embargo, el aprendizaje no supervisado puede ser más impredecible en comparación con otros métodos de aprendizaje profundo y de refuerzo.
¿Por qué usar el aprendizaje supervisado?
El aprendizaje supervisado te permite recopilar datos o producir una salida de datos basada en experiencias previas.
Ayuda a optimizar los criterios de rendimiento utilizando la experiencia.
El aprendizaje automático supervisado te ayuda a resolver varios tipos de problemas de computación del mundo real.
¿Por qué usar el aprendizaje no supervisado?
Estas son las principales razones para utilizar el aprendizaje no supervisado:
El aprendizaje no supervisado encuentra todo tipo de patrones desconocidos en los datos.
Los métodos no supervisados te ayudan a descubrir características que pueden ser útiles para la categorización.
Se lleva a cabo en tiempo real, lo que permite analizar y etiquetar todos los datos de entrada en presencia del modelo.
Mira Tambien Mejores Chatbots de Inteligencia Artificial:
Mejores Chatbots de Inteligencia Artificial: Es más fácil obtener datos sin etiquetar de una computadora que obtener datos etiquetados, que requieren intervención manual.
¿Cómo funciona el aprendizaje supervisado?
Por ejemplo, supongamos que deseas entrenar una máquina para ayudarte a predecir cuánto tiempo te llevará conducir desde tu lugar de trabajo hasta tu casa.
Comienzas creando un conjunto de datos etiquetados que incluyen detalles como :
condiciones climáticas
hora del día
y si es día festivo .
Estos detalles se consideran como las entradas del modelo, mientras que el resultado deseado es la cantidad de tiempo que llevó conducir de regreso a casa en un día específico.

Siendo intuitivo, sabes que si está lloviendo, probablemente te llevará más tiempo conducir a casa.
Sin embargo, la máquina requiere datos y estadísticas para realizar estas predicciones.
Veamos cómo puedes desarrollar un modelo de aprendizaje supervisado en este ejemplo para ayudarte a determinar el tiempo de viaje. Primero, debes crear un conjunto de datos de entrenamiento que contenga el tiempo total de viaje junto con los factores correspondientes, como el clima y la hora del día. Basado en este conjunto de entrenamiento, la máquina puede identificar una relación directa entre la cantidad de lluvia y el tiempo requerido para llegar a casa.
Por lo tanto, el modelo aprende que a medida que aumenta la cantidad de lluvia, el tiempo de viaje aumenta. También puede reconocer la conexión entre la hora de salida del trabajo y el tiempo que tomará estar en la carretera.
A medida que se acerca más a las 6 p.m., el tiempo de viaje tiende a ser mayor. La máquina puede descubrir algunas de estas relaciones utilizando los datos etiquetados.

Esto marca el comienzo de tu modelo de datos, ya que comienzas a comprender cómo la lluvia afecta la forma en que las personas conducen y observas que más personas viajan en un momento específico del día.
Mira Tambien¿Cómo funciona el aprendizaje no supervisado?
Tomemos el caso de un bebé y el perro de su familia.

El bebé conoce e identifica a este perro. Unas semanas más tarde, un amigo de la familia trae otro perro e intenta jugar con el bebé.

El bebé no ha visto a este perro antes, pero reconoce que comparte muchas características con su perro mascota, como tener 2 orejas, ojos y caminar sobre 4 patas. El bebé identifica al nuevo animal como un perro. Este es un ejemplo de aprendizaje no supervisado, donde no se le enseña al bebé, pero aprende a partir de los datos disponibles (en este caso, datos sobre un perro). Si esto hubiera sido un aprendizaje supervisado, el amigo de la familia le habría dicho al bebé que se trata de un perro
Regresión:
La técnica de regresión se utiliza para predecir un valor único de salida utilizando datos de entrenamiento.
Por ejemplo, podemos usar la regresión para predecir el precio de una vivienda utilizando variables de entrada como la ubicación y el tamaño de la casa.
Clasificación:
La clasificación implica agrupar la salida en categorías o clases. Cuando el algoritmo intenta etiquetar la entrada en dos clases distintas, se denomina clasificación binaria. Si se seleccionan más de dos clases, se denomina clasificación multiclase.
ejemplo:, se puede utilizar la clasificación para determinar si alguien será o no un moroso de un préstamo.
Puntos fuertes: Las salidas de clasificación siempre tienen una interpretación probabilística y el algoritmo se puede regularizar para evitar el sobreajuste.
Debilidades: La regresión logística puede tener un rendimiento inferior cuando existen límites de decisión múltiples o no lineales. Este método no es muy flexible y puede no capturar relaciones más complejas.
Tipos de técnicas de aprendizaje automático no supervisado:
Los problemas de aprendizaje no supervisado se agrupan en problemas de agrupación y asociación.

El agrupamiento es un concepto fundamental en el aprendizaje no supervisado, y se refiere a encontrar estructuras o patrones en conjuntos de datos no categorizados. Los algoritmos de agrupamiento analizan los datos y encuentran agrupaciones naturales o grupos si existen en los datos. También es posible ajustar la cantidad de clusters que los algoritmos deben identificar, lo que permite ajustar la granularidad de dichos grupos.
Asociación: se refiere a establecer relaciones entre objetos de datos dentro de grandes bases de datos. Las reglas de asociación son utilizadas en esta técnica no supervisada para descubrir relaciones interesantes entre variables en bases de datos extensas. Por ejemplo, las personas que compran una casa nueva es probable que también compren muebles nuevos.
Aquí hay algunos ejemplos adicionales:
- Agrupar un subgrupo de pacientes con cáncer según sus perfiles de expresión génica.
- Agrupar compradores basados en su historial de navegación y compras.
- Agrupar películas según las calificaciones otorgadas por los espectadores
| Parámetros | Técnica de aprendizaje automático supervisado | Técnica de aprendizaje automático no supervisado |
|---|---|---|
| Proceso | Se dan variables de entrada y salida | Solo se proporcionan datos de entrada |
| Datos de entrada | Utiliza datos etiquetados | Utiliza datos no etiquetados |
| Algoritmos utilizados | Máquina de vectores de soporte, red neuronal, regresión lineal y logística, bosque aleatorio y árboles de clasificación | Algoritmos de clúster, K-means, agrupamiento jerárquico, etc. |
| Complejidad computacional | Menos complejo computacionalmente | Más complejo computacionalmente |
| Uso de datos | Utiliza datos de entrenamiento para aprender una relación entre entrada y salida | No utiliza datos de salida |
| Precisión de los resultados | Alta precisión y confiabilidad | Menos precisión y confiabilidad |
| Aprendizaje en tiempo real | Se realiza fuera de línea | Se realiza en tiempo real |
| Número de clases | El número de clases es conocido | El número de clases no es conocido |
| Principal inconveniente | Clasificar grandes datos puede ser un desafío | No proporciona información precisa sobre la clasificación de datos, ya que los datos utilizados no están etiquetados |
 «Charlando con la Inteligencia: Los Mejores Chatbots en Acción»
«Charlando con la Inteligencia: Los Mejores Chatbots en Acción»Lecciones anteriores:
- LECCION 1) ¿Qué es la Inteligencia Artificial? Introducción, Historia y Tipos de IA
- LECCION 2) Sistema Experto en IA: Aprende con Ejemplos
- LECCION 3) Aprendizaje Automático para Principiantes: Conceptos Básicos de ML
- LECCION 4) Matriz de Confusión en el Aprendizaje Automático: Aprende con Ejemplos
- LECCION 5 ) Aprendizaje Profundo para Principiantes: Proceso y Tipos
- LECCION 6 ) Aprendizaje Automático Supervisado: Algoritmos con Ejemplos
- LECCION 7) Aprendizaje Automático No Supervisado: Algoritmos, Tipos con Ejemplo
- LECCION 8) Red Neuronal de Retropropagación: Cómo Funciona el Algoritmo de Retropropagación
- LECCION 9) Aprendizaje por Refuerzo: Algoritmos, Tipos y Ejemplos
- LECCION 10)Tutorial de Lógica Difusa: Arquitectura, Aplicación, Ejemplo
- LECCION 11) Aplicaciones de la IA: 13 Ejemplos de IA que Debes Conocer y sus Diferencias
Debe saber las diferencias!
SIGUIENTE: