¿Que se entiende por aprendizaje por refuerzo?(o Reinforcement Learning)
¿Qué es el aprendizaje por refuerzo? El aprendizaje por refuerzo se define como un método de aprendizaje automático que aborda la forma en que los agentes de software deben realizar acciones en un entorno. Es una parte del aprendizaje profundo que busca maximizar una recompensa acumulativa. El aprendizaje por refuerzo permite a las redes neuronales aprender cómo lograr objetivos complejos o maximizar una dimensión específica a lo largo de múltiples pasos.
En este tutorial de aprendizaje por refuerzo, exploraremos los siguientes aspectos:
- Definición y concepto del aprendizaje por refuerzo
- Componentes importantes del método de aprendizaje por refuerzo profundo
- Funcionamiento del aprendizaje por refuerzo
- Algoritmos utilizados en el aprendizaje por refuerzo
- Características distintivas del aprendizaje por refuerzo
- Diferencias entre el aprendizaje por refuerzo y el aprendizaje supervisado
- Tipos y modelos de aprendizaje por refuerzo
- Aplicaciones prácticas del aprendizaje por refuerzo
- Ventajas y casos de uso del aprendizaje por refuerzo
- Consideraciones y desafíos asociados al aprendizaje por refuerzo
Componentes importantes del método de aprendizaje por refuerzo profundo
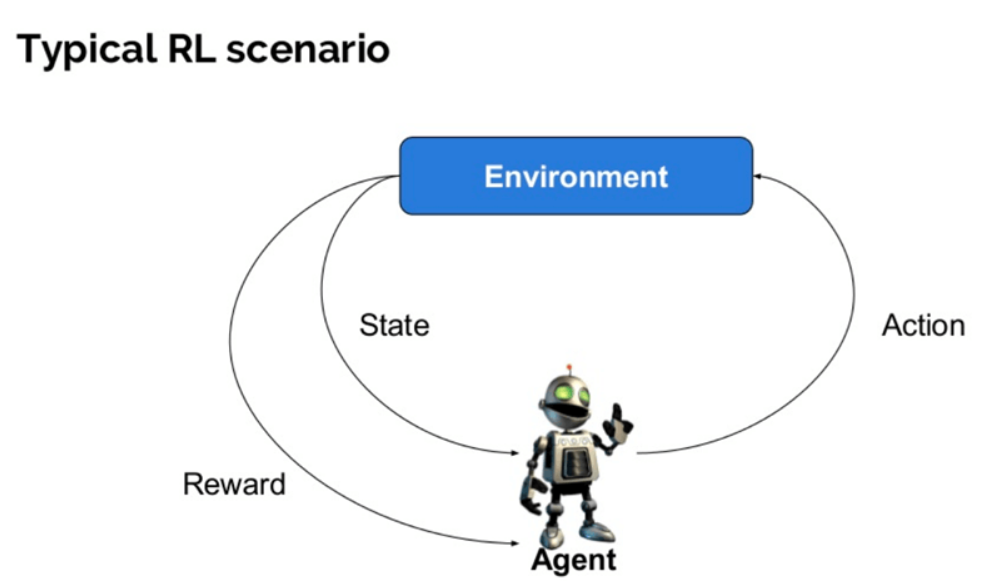
El aprendizaje por refuerzo profundo utiliza varios términos clave que son fundamentales para comprender su funcionamiento:
- Agente: Es una entidad que realiza acciones en un entorno con el objetivo de obtener recompensas.
- Entorno (e): Es el escenario en el que el agente interactúa y toma decisiones.
- Recompensa (R): Es el retorno inmediato otorgado al agente cuando realiza una acción o tarea específica.
- Estado (s): Se refiere a la situación actual del entorno, que puede ser observada o inferida por el agente.
- Política (π): Es una estrategia que el agente utiliza para decidir la próxima acción en función del estado actual.
- Valor (V): Representa la rentabilidad esperada a largo plazo con descuento, en comparación con las recompensas a corto plazo. Indica la utilidad de un estado en particular.
- Función de Valor: Especifica el valor de un estado, que es la cantidad total de recompensa esperada que se puede obtener a partir de ese estado. Ayuda al agente a evaluar la calidad de los estados y a tomar decisiones basadas en ello.
- Modelo del entorno: Es una representación que imita el comportamiento del entorno. Permite al agente hacer inferencias y predecir cómo se comportará el entorno en diferentes situaciones.
- Métodos basados en modelos: Son enfoques utilizados en el aprendizaje por refuerzo que emplean modelos del entorno para tomar decisiones y aprender de ellos.
- Valor Q o valor de acción (Q): Es similar al valor, pero toma un parámetro adicional que representa la acción actual. El valor Q indica la utilidad esperada de tomar una acción específica en un estado determinado.
¿Cómo funciona el aprendizaje por refuerzo?
Veamos un ejemplo sencillo que ilustra el mecanismo del aprendizaje por refuerzo.
Imaginemos que queremos enseñarle nuevos trucos a nuestro gato. Dado que el gato no entiende el lenguaje humano, no podemos simplemente decirle qué hacer. En cambio, seguimos una estrategia diferente.
Creamos una situación específica y el gato intenta responder de diferentes maneras. Si el gato realiza la acción deseada, le recompensamos con comida, como un trozo de pescado.
Cada vez que el gato se encuentra en la misma situación, intenta ejecutar una acción similar con aún más entusiasmo, esperando obtener más recompensas. Aprenden de las experiencias positivas qué acciones les llevan a recibir la recompensa deseada.
Al mismo tiempo, el gato también aprende qué acciones evitar basándose en experiencias negativas. Si una acción no conduce a una recompensa o resulta en una consecuencia negativa, el gato aprende a no repetir esa acción en futuras ocasiones.
En resumen, el aprendizaje por refuerzo implica el proceso de aprender a través de la interacción de un agente con su entorno. El agente aprende a tomar decisiones que maximizan las recompensas a largo plazo y evitan las consecuencias negativas, basándose en la retroalimentación proporcionada por el entorno.
Ejemplo de aprendizaje por refuerzo

| Estado (S) | Acción (A) | Recompensa (R) | Nuevo Estado (S’) |
|---|---|---|---|
| S0 | A0 | R0 | S1 |
| S1 | A1 | R1 | S2 |
| S2 | A2 | R2 | S3 |
| S3 | A3 | R3 | S4 |
| S4 | A4 | R4 | S5 |
Cómo funciona el aprendizaje por refuerzo
En esta tabla, cada fila representa una transición entre estados. El agente se encuentra en un estado inicial S0 y toma una acción A0. Como resultado, recibe una recompensa R0 y pasa al siguiente estado S1. Esto se repite en cada paso del proceso de aprendizaje.
El objetivo del aprendizaje por refuerzo es que el agente aprenda a tomar las acciones óptimas en cada estado para maximizar las recompensas acumuladas a largo plazo. A medida que el agente explora el entorno y recibe retroalimentación en forma de recompensas, ajusta sus estrategias de toma de decisiones para mejorar su desempeño y lograr mejores resultados.
Mira Tambien Tutorial de Lógica Difusa: Arquitectura, Aplicación, Ejemplo
Tutorial de Lógica Difusa: Arquitectura, Aplicación, EjemploAquí tienes una tabla de ejemplo que ilustra el proceso de aprendizaje por refuerzo:
| Estado Actual | Acción Realizada | Estado Siguiente | Recompensa |
|---|---|---|---|
| Sentado | «Caminar» | Caminando | +1 |
| Caminando | «Saltar» | Saltando | +2 |
| Sentado | «Saltar» | Saltando | -1 |
| Saltando | «Maullar» | Saltando | -2 |
| Caminando | «Maullar» | Sentado | -1 |
En este ejemplo, el estado inicial es «Sentado». El agente realiza la acción de «Caminar» y se encuentra en el estado «Caminando», donde recibe una recompensa de +1. Luego, el agente realiza la acción de «Saltar» y pasa al estado «Saltando», recibiendo una recompensa adicional de +2. Sin embargo, cuando el agente intenta saltar mientras está sentado, recibe una penalización de -1. Del mismo modo, cuando intenta maullar mientras está saltando o caminando, recibe una penalización de -2 y -1 respectivamente.
A través de la interacción con el entorno y la recepción de recompensas o penalizaciones, el agente aprende a tomar decisiones que maximicen las recompensas a largo plazo. El objetivo es que el agente aprenda a realizar las acciones correctas en los estados adecuados para maximizar la recompensa acumulada a lo largo del tiempo.
Algoritmos de aprendizaje por refuerzo
Existen tres enfoques para implementar un algoritmo de aprendizaje por refuerzo.
Basado en valores
- En el método de aprendizaje por refuerzo basado en valores, el objetivo es maximizar una función de valor V(s). En este enfoque, el agente busca obtener un rendimiento a largo plazo de los estados actuales siguiendo una política π.
- Basado en políticas: En el método de aprendizaje por refuerzo basado en políticas, se busca crear una política que maximice la recompensa futura. Se pueden distinguir dos tipos de métodos basados en políticas: a.Determinista: En este caso, para cualquier estado, la política π produce la misma acción de manera determinista. b. Estocástico: En este caso, cada acción tiene una cierta probabilidad, que está determinada por la función de probabilidad P(a|s), lo que da lugar a una política estocástica. n{a\s) = P\A, = a\S, =S]
- Basado en modelos: En este método de aprendizaje por refuerzo, se crea un modelo virtual para cada entorno. El agente aprende a actuar en ese entorno específico, utilizando el modelo para tomar decisiones y mejorar su rendimiento.
Características del aprendizaje por refuerzo
Aquí se presentan algunas características importantes del aprendizaje por refuerzo:
- Ausencia de supervisor: En el aprendizaje por refuerzo, no hay un supervisor directo que indique las acciones correctas. En su lugar, se utiliza una señal de recompensa o número real para guiar el aprendizaje.
- Toma de decisiones secuencial: El aprendizaje por refuerzo implica tomar decisiones en secuencia, donde las acciones realizadas tienen impacto en los datos y resultados futuros.
- Importancia del tiempo: El factor tiempo es crucial en los problemas de refuerzo. Las decisiones tomadas en momentos específicos pueden influir en las recompensas obtenidas y en el rendimiento general del agente.
- Retraso en la retroalimentación: A diferencia de otros enfoques de aprendizaje, la retroalimentación en el aprendizaje por refuerzo no es instantánea. Existe un retraso entre la acción y la retroalimentación recibida, lo que hace que la toma de decisiones sea más desafiante.
Tipos de aprendizaje por refuerzo
Existen dos tipos de métodos de aprendizaje por refuerzo:
- Refuerzo positivo: Este tipo de refuerzo ocurre cuando un evento recompensador se asocia con un comportamiento específico. Aumenta la probabilidad y la frecuencia de la conducta y tiene un impacto positivo en las acciones del agente. Ayuda a maximizar el rendimiento y mantener cambios a largo plazo, aunque un exceso de refuerzo puede llevar a la optimización extrema y afectar los resultados.
- Refuerzo negativo: El refuerzo negativo se produce cuando una conducta se fortalece debido a la eliminación o evitación de una condición negativa. Define el rendimiento mínimo requerido y ayuda a evitar consecuencias adversas. Sin embargo, su limitación es que solo proporciona suficiente incentivo para cumplir con el nivel mínimo de rendimiento.
Modelos de Aprendizaje por Refuerzo
Existen dos modelos importantes en el aprendizaje por refuerzo
Proceso de decisión de Markov
q aprendizaje
Proceso de decisión de Markov
Los siguientes parámetros se utilizan para obtener una solución:
Conjunto de acciones- A
Mira Tambien ¿Qué es la ciencia de datos? Introducción, conceptos básicos y proceso
¿Qué es la ciencia de datos? Introducción, conceptos básicos y procesoConjunto de estados -S
Recompensa- R
Política- n
Valor- V
El enfoque matemático para mapear una solución en el aprendizaje por refuerzo se reconoce como un proceso de decisión de Markov o (MDP).
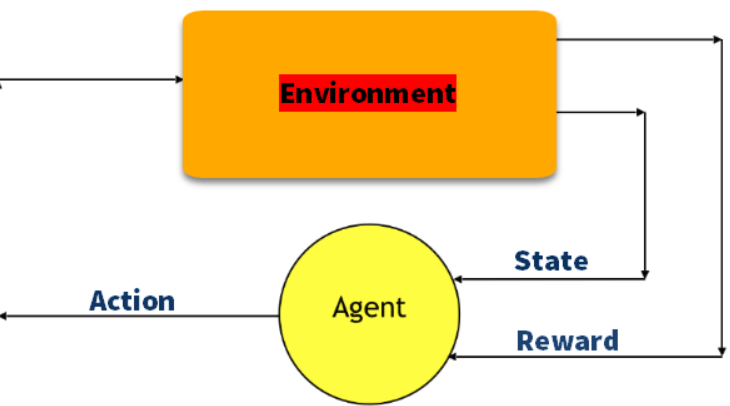
Q-aprendizaje
Q learning es un método basado en valores para proporcionar información para saber qué acción debe tomar un agente.
Entendamos este método con el siguiente ejemplo:
Hay cinco habitaciones en un edificio que están conectadas por puertas. Cada habitación está numerada del 0 al 4 El exterior del edificio puede ser una gran área exterior (5) Las puertas número 1 y 4 conducen al edificio desde la habitación 5

A continuación, es necesario asignar un valor de recompensa a cada puerta según las siguientes reglas:
- Las puertas que conducen directamente a la meta tienen una recompensa de 100.
- Las puertas que no están directamente conectadas a la habitación objetivo no proporcionan ninguna recompensa.
- Dado que las puertas son de doble sentido, se asignan dos flechas para cada habitación.
- Cada flecha en la imagen de arriba representa un valor de recompensa instantáneo.
Explicación:
En la imagen, cada habitación representa un estado. El movimiento del agente de una habitación a otra representa una acción.
En la imagen de abajo, cada estado se representa como un nodo, mientras que las flechas indican las acciones.

Por ejemplo, si un agente se mueve de la habitación número 2 a la 5, se seguiría el siguiente recorrido:
Mira Tambien Ciencia de Datos vs. Aprendizaje Automático: Diferencias y Funciones
Ciencia de Datos vs. Aprendizaje Automático: Diferencias y Funciones- Estado inicial: Habitación 2.
- Movimiento: Estado 2 -> Estado 3.
- Movimiento: Estado 3 -> Estado (2, 1, 4).
- Movimiento: Estado 4 -> Estado (0, 5, 3).
- Movimiento: Estado 1 -> Estado (5, 3).
- Movimiento: Estado 0 -> Estado 4.
Aprendizaje por refuerzo versus aprendizaje supervisado
| Parámetros | Aprendizaje por Refuerzo | Aprendizaje Supervisado |
|---|---|---|
| Estilo de decisión | Ayuda a tomar decisiones secuencialmente | Toma una decisión basada en la entrada dada |
| Funciona en | Interacción con el entorno | Ejemplos o datos de muestra dados |
| Dependencia de decisión | Decisiones dependientes, requiere etiquetas para todas las decisiones | Decisiones independientes, se asignan etiquetas a cada decisión |
| Más adecuado | Predominantemente en IA, donde hay interacción humana | Principalmente en sistemas de software interactivo o aplicaciones |
| Ejemplo | Ajedrez | Reconocimiento de objetos |
Aplicaciones del Aprendizaje por Refuerzo
El aprendizaje por refuerzo tiene diversas aplicaciones, entre las que se incluyen:
- Robótica para la automatización industrial.
- Planificación de estrategias empresariales.
- Aprendizaje automático y procesamiento de datos.
- Creación de sistemas de capacitación que proporcionan instrucción y materiales personalizados según los requisitos de los estudiantes.
- Control de aeronaves y control de movimiento de robots.
Ventajas del Aprendizaje por Refuerzo
Existen varias razones principales para utilizar el aprendizaje por refuerzo:
- Ayuda a determinar en qué situaciones se necesita una acción.
- Permite descubrir qué acciones generan la mayor recompensa a lo largo del tiempo.
- Proporciona al agente de aprendizaje una función de recompensa.
- Facilita el descubrimiento de los métodos óptimos para obtener grandes recompensas.
Cuándo no utilizar el Aprendizaje por Refuerzo
El modelo de aprendizaje por refuerzo no es aplicable en todas las situaciones. Aquí hay algunas condiciones en las que no se debe utilizar el aprendizaje por refuerzo:
- Cuando se disponga de suficientes datos para resolver el problema mediante un método de aprendizaje supervisado.
- Es importante tener en cuenta que el aprendizaje por refuerzo requiere mucho tiempo y recursos informáticos, especialmente cuando el espacio de acción es grande.
Desafíos del Aprendizaje por Refuerzo
Al aplicar el aprendizaje por refuerzo, se enfrentarán a los siguientes desafíos principales:
- Diseño de características/recompensas: Es necesario estar muy involucrado en el diseño de las características y recompensas del sistema, ya que estas pueden influir significativamente en los resultados del aprendizaje.
- Influencia de los parámetros: Los parámetros utilizados en el aprendizaje por refuerzo pueden afectar la velocidad de aprendizaje y los resultados obtenidos. Se requiere un ajuste cuidadoso de estos parámetros para obtener un buen rendimiento.
- Observabilidad parcial: En entornos realistas, puede existir una observabilidad parcial, lo que significa que el agente solo puede observar una parte limitada del entorno. Esto puede dificultar la toma de decisiones precisas.
- Sobrecarga de estados: Un exceso de refuerzo puede conducir a una sobrecarga de estados, lo que implica un gran número de posibles estados del sistema. Esto puede disminuir los resultados del aprendizaje y dificultar la generalización efectiva del agente.
- Entornos no estacionarios: Los entornos realistas pueden cambiar con el tiempo, lo que se conoce como no estacionariedad. Esto añade complejidad al aprendizaje, ya que el agente debe adaptarse a los cambios en el entorno para seguir tomando decisiones óptimas
Resumen:
El aprendizaje por refuerzo es un método de aprendizaje automático que busca descubrir qué acciones producen la mayor recompensa a largo plazo. Se utilizan tres métodos en el aprendizaje por refuerzo: basado en valores, basado en políticas y basado en modelos. Los términos importantes en este método incluyen agente, estado, recompensa, entorno, función de valor y modelo del entorno.
Un ejemplo común del aprendizaje por refuerzo es imaginar que tu gato es un agente que interactúa con su entorno. La característica distintiva de este método es que no hay un supervisor, solo una señal de recompensa que guía al agente.
Existen dos tipos de aprendizaje por refuerzo: positivo y negativo. Los modelos ampliamente utilizados en el aprendizaje por refuerzo son el proceso de decisión de Markov y el aprendizaje Q.
El aprendizaje por refuerzo se aplica en diversas áreas, como la robótica para la automatización industrial y la planificación de estrategias comerciales. Sin embargo, no se debe utilizar este método cuando se dispone de suficientes datos para resolver el problema.
Uno de los principales desafíos del aprendizaje por refuerzo es la influencia de los parámetros en la velocidad de aprendizaje.
LECCIONES ANTERIORES:
- LECCION 1) ¿Qué es la Inteligencia Artificial? Introducción, Historia y Tipos de IA
- LECCION 2) Sistema Experto en IA: Aprende con Ejemplos
- LECCION 3) Aprendizaje Automático para Principiantes: Conceptos Básicos de ML
- LECCION 4) Matriz de Confusión en el Aprendizaje Automático: Aprende con Ejemplos
- LECCION 5 ) Aprendizaje Profundo para Principiantes: Proceso y Tipos
- LECCION 6 ) Aprendizaje Automático Supervisado: Algoritmos con Ejemplos
- LECCION 7) Aprendizaje Automático No Supervisado: Algoritmos, Tipos con Ejemplo
- LECCION 8) Red Neuronal de Retropropagación: Cómo Funciona el Algoritmo de Retropropagación
Siguiente lección :
Mira Tambien Tutorial de SAS para principiantes: Qué es y ejemplo de programación
Tutorial de SAS para principiantes: Qué es y ejemplo de programaciónLECCION 10)Tutorial de Lógica Difusa: Arquitectura, Aplicación, Ejemplo