Diferencia clave entre el aprendizaje automático y el aprendizaje profundo
Las principales diferencias entre el Machine Learning y el Deep Learning son:
El aprendizaje automático proporciona un rendimiento excelente en un conjunto de datos pequeño o mediano, mientras que el aprendizaje profundo proporciona un rendimiento excelente en un conjunto de datos grande.
El ML funciona en una máquina de gama baja, mientras que el DL requiere una máquina potente, preferiblemente con GPU.
El tiempo de ejecución del aprendizaje automático va de unos minutos a horas, mientras que el aprendizaje profundo puede llevar semanas.
Con el aprendizaje automático, se necesita menos datos para entrenar el algoritmo en comparación con el aprendizaje profundo. El aprendizaje profundo requiere un conjunto extenso y diverso de datos para identificar la estructura subyacente.
En este tutorial de ML vs DL, aprenderás:
- ¿Qué es la IA?
- ¿Qué es el aprendizaje automático (ML)?
- ¿Qué es el aprendizaje profundo (DL)?
- Diferencia entre aprendizaje automático y aprendizaje profundo.
- ¿Cuándo usar ML o DL?
- Proceso de aprendizaje automático.
- Proceso de aprendizaje profundo.
- Automatizar la extracción de características usando DL.
- Resumen
¿Qué es la IA?
La IA, o inteligencia artificial, es un campo de la informática que se enfoca en desarrollar sistemas y programas capaces de realizar tareas que requieren de inteligencia humana. El objetivo de la IA es crear máquinas que puedan pensar, razonar, aprender y tomar decisiones de manera similar a los seres humanos.
La IA se basa en algoritmos y modelos matemáticos que permiten a las máquinas procesar grandes cantidades de datos, identificar patrones, reconocer imágenes, comprender el lenguaje natural, tomar decisiones y resolver problemas. Estas capacidades cognitivas permiten a las máquinas realizar tareas específicas de manera más eficiente y precisa que los humanos en algunos casos.
Existen diferentes niveles de IA:
- IA estrecha: Se refiere a sistemas de IA diseñados para realizar una tarea específica de manera experta, superando incluso a los humanos en esa tarea en particular. Los ejemplos comunes de IA estrecha incluyen sistemas de reconocimiento de voz, chatbots, asistentes virtuales y sistemas de recomendación.
- IA general: Se trata de una IA que puede realizar cualquier tarea intelectual que un ser humano pueda hacer. Este nivel de IA aún no se ha alcanzado plenamente y sigue siendo objeto de investigación y desarrollo.
- IA superinteligente: Hace referencia a una IA que es más inteligente que los seres humanos en todas las áreas cognitivas y puede superar ampliamente nuestras capacidades en diversas tareas. Este nivel de IA es puramente teórico y su existencia es objeto de debate y especulación.
En cuanto a los métodos utilizados en los primeros sistemas de IA, se basaban principalmente en el uso de algoritmos de coincidencia de patrones y sistemas expertos. Sin embargo, con los avances en la tecnología, se han desarrollado enfoques más sofisticados, como el aprendizaje automático (Machine Learning) y el aprendizaje profundo (Deep Learning), que permiten a las máquinas aprender de los datos y mejorar su rendimiento de manera autónoma.
Mira Tambien Aprendizaje profundo vs aprendizaje automatico cual es la diferencia
Aprendizaje profundo vs aprendizaje automatico cual es la diferenciaEn resumen, la IA busca crear máquinas capaces de realizar tareas que requieren de inteligencia humana, utilizando diferentes métodos y enfoques para lograrlo.
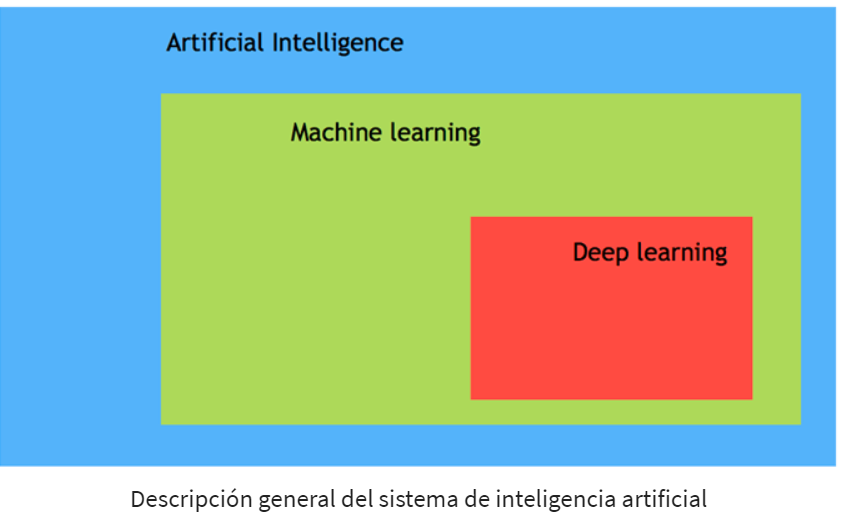
¿Qué es el aprendizaje automático (ML)?
El aprendizaje automático (Machine Learning) es un tipo de IA en el que se entrena una computadora para automatizar tareas que son exhaustivas o imposibles para los seres humanos. Es la mejor herramienta para analizar, comprender e identificar patrones en datos, basándose en el estudio de algoritmos informáticos. El aprendizaje automático puede tomar decisiones con una mínima intervención humana.
Al comparar la inteligencia artificial con el aprendizaje automático, este último utiliza datos para alimentar un algoritmo que puede comprender la relación entre la entrada y la salida. Cuando la máquina ha terminado de aprender, puede predecir el valor o la clase de un nuevo punto de datos.
¿Qué es el aprendizaje profundo (DL)?
El aprendizaje profundo (Deep Learning) es un software de computadora que imita la red de neuronas en un cerebro. Es un subconjunto del aprendizaje automático y se denomina aprendizaje profundo porque utiliza redes neuronales profundas. La máquina utiliza diferentes capas para aprender de los datos. La profundidad del modelo está representada por el número de capas en el modelo. El aprendizaje profundo es el nuevo estado del arte en términos de IA. En el aprendizaje profundo, la fase de aprendizaje se realiza a través de una red neuronal, donde las capas se apilan una encima de la otra.
Diferencia entre aprendizaje automático y aprendizaje profundo
A continuación se muestra una diferencia clave entre el aprendizaje profundo y el aprendizaje automático:
| Parámetro | Aprendizaje automático | Aprendizaje profundo |
|---|---|---|
| Dependencias de datos | Excelentes rendimientos en un conjunto de datos pequeño/mediano | Excelente rendimiento en un gran conjunto de datos |
| Dependencias de hardware | Trabaja en una máquina de gama baja | Requiere una máquina potente, preferiblemente con GPU: el aprendizaje profundo realiza una cantidad significativa de multiplicación de matrices |
| Ingeniería de características | Necesidad de comprender las características que representan los datos | No es necesario comprender cuál es la mejor característica que representa los datos |
| Tiempo de ejecución | De unos minutos a horas | Hasta semanas: las redes neuronales necesitan calcular una cantidad significativa de pesos |
| Interpretabilidad | Algunos algoritmos son fáciles de interpretar (logística, árbol de decisión), otros son casi imposibles (SVM, XGBoost) | Difícil a imposible |
¿Cuándo usar ML o DL?
En la siguiente tabla, resumimos la diferencia entre el aprendizaje automático y el aprendizaje profundo con ejemplos:
| Parámetro | Aprendizaje automático | Aprendizaje profundo |
|---|---|---|
| Conjunto de datos de entrenamiento | Pequeño | Grande |
| Elige características | Sí | No |
| Número de algoritmos | Muchos | Pocos |
| Tiempo de entrenamiento | Corto | Largo |
Con el aprendizaje automático, se necesita menos datos para entrenar el algoritmo en comparación con el aprendizaje profundo. El aprendizaje profundo requiere un conjunto extenso y diverso de datos para identificar la estructura subyacente. Además, el aprendizaje automático proporciona un modelo entrenado más rápido. La arquitectura de aprendizaje profundo más avanzada puede tardar desde días hasta una semana en entrenarse. La ventaja del aprendizaje profundo sobre el aprendizaje automático es su alta precisión. No es necesario comprender qué características son la mejor representación de los datos, ya que la red neuronal aprende a seleccionar características críticas. En el aprendizaje automático, es necesario elegir por uno mismo qué características incluir en el modelo.
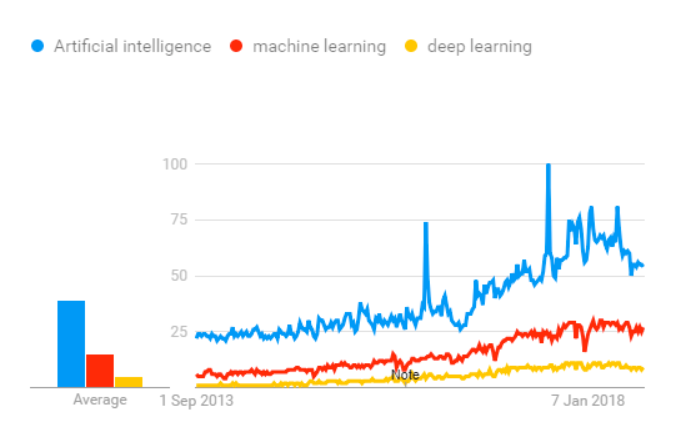
Proceso de aprendizaje automático
Imagina que estás destinado a construir un programa que reconozca objetos. Para entrenar el modelo, utilizarás un clasificador. Un clasificador utiliza las características de un objeto para intentar identificar la clase a la que pertenece.
En el ejemplo, el clasificador será entrenado para detectar si la imagen corresponde a los siguientes objetos:
- Bicicleta
- Bote
- Auto
- Avión
Estos cuatro objetos son las clases que el clasificador debe reconocer. Para construir un clasificador, necesitas tener algunos datos como entrada y asignarles una etiqueta. El algoritmo tomará estos datos, encontrará un patrón y luego los clasificará en la clase correspondiente.
Mira TambienEsta tarea se llama aprendizaje supervisado. En el aprendizaje supervisado, los datos de entrenamiento que alimentas al algoritmo incluyen una etiqueta.
El proceso de entrenar un algoritmo de aprendizaje automático sigue algunos pasos estándar:
- Recopilar los datos.
- Entrenar el clasificador.
- Hacer predicciones.
El primer paso es crucial, ya que elegir los datos correctos determinará si el algoritmo tiene éxito o fracasa. Los datos que eliges para entrenar el modelo se llaman características. En el ejemplo de los objetos, las características son los píxeles de las imágenes.
Cada imagen se representa como una fila en los datos, mientras que cada píxel se representa como una columna. Si tu imagen tiene un tamaño de 28×28 píxeles, el conjunto de datos contendrá 784 columnas (28×28). En la imagen de abajo, cada imagen se ha transformado en un vector de características. La etiqueta le indica a la computadora qué objeto se encuentra en la imagen.
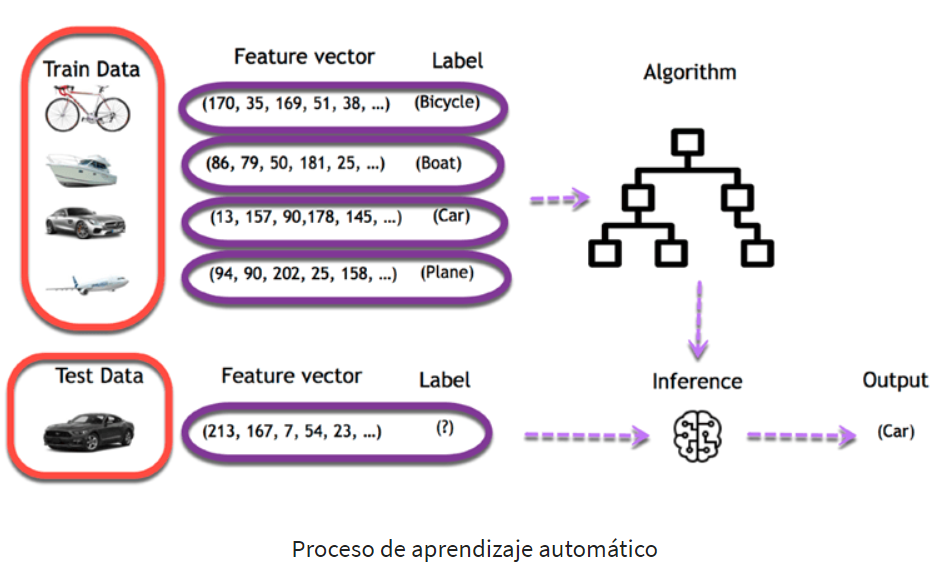
El objetivo es utilizar estos datos de entrenamiento para clasificar el tipo de objeto. El primer paso consiste en crear las columnas de características. Luego, el segundo paso implica elegir un algoritmo para entrenar el modelo. Una vez finalizado el entrenamiento, el modelo podrá predecir a qué clase pertenece cada imagen.
Después de eso, es fácil utilizar el modelo para hacer predicciones sobre nuevas imágenes. Para cada nueva imagen introducida en el modelo, la máquina hará una predicción sobre la clase a la que pertenece. Por ejemplo, si se introduce una imagen completamente nueva sin etiqueta en el modelo, la máquina utilizará su conocimiento previo para predecir que la imagen se trata de un automóvil. Al igual que un ser humano, la máquina usará su capacidad de reconocimiento para realizar estas predicciones.
Proceso de aprendizaje profundo
En el aprendizaje profundo, la fase de aprendizaje se realiza a través de una red neuronal. Una red neuronal es una arquitectura en la que las capas se apilan una encima de la otra.
Consideremos el mismo ejemplo de imágenes anterior. El conjunto de entrenamiento se alimentaría a una red neuronal.
Cada entrada entra en una neurona y se multiplica por un peso. El resultado de la multiplicación fluye hacia la siguiente capa y se convierte en la entrada para esa capa. Este proceso se repite para cada capa de la red. La capa final se conoce como capa de salida, y proporciona un valor real para tareas de regresión o una probabilidad para cada clase en tareas de clasificación. La red neuronal utiliza un algoritmo matemático para actualizar los pesos de todas las neuronas. La red neuronal está completamente entrenada cuando el valor de los pesos produce una salida cercana a la realidad. Por ejemplo, una red neuronal bien entrenada puede reconocer objetos en imágenes con mayor precisión que una red neuronal tradicional.
El aprendizaje profundo permite a la red neuronal aprender automáticamente las características relevantes a partir de los datos de entrenamiento, sin necesidad de que los humanos especifiquen manualmente qué características utilizar. Esto es especialmente útil en tareas donde las características son complejas y difíciles de definir explícitamente.
Mira Tambien Mejores Chatbots de Inteligencia Artificial:
Mejores Chatbots de Inteligencia Artificial: En resumen, el proceso de aprendizaje profundo involucra la utilización de redes neuronales apiladas para aprender y extraer características automáticamente de los datos de entrenamiento, lo que permite realizar predicciones más precisas y sofisticadas en comparación con enfoques tradicionales de aprendizaje automático.
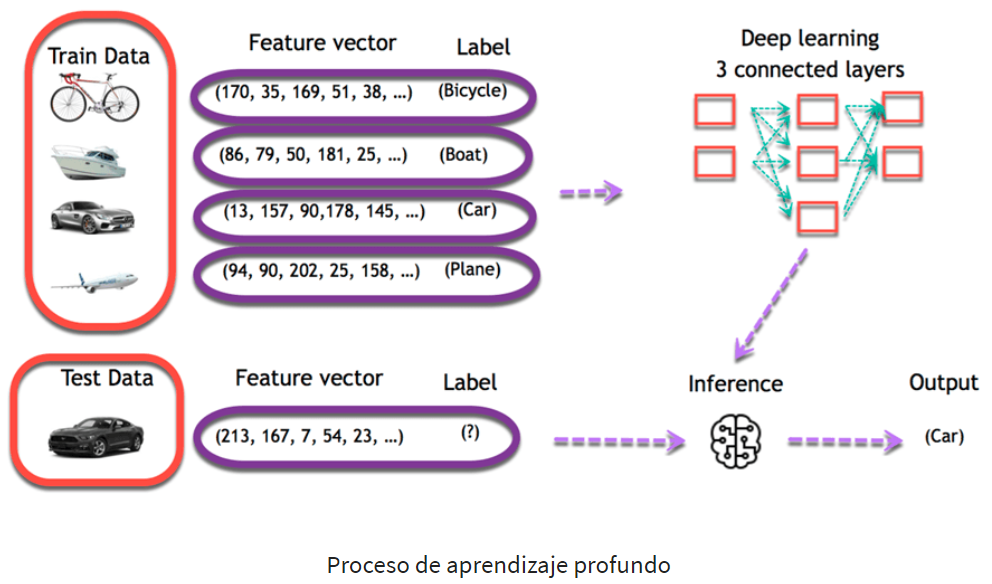
Automatizar la extracción de características utilizando DL (Deep Learning)
Un conjunto de datos puede contener desde una docena hasta cientos de características. El sistema aprenderá la relevancia de estas características. Sin embargo, nem todas las características son significativas para el algoritmo. Una parte crucial del aprendizaje automático es encontrar un conjunto relevante de características para que el sistema aprenda algo.
Una forma de abordar esta parte del aprendizaje automático es mediante la extracción de características. La extracción de características combina las características existentes para crear un conjunto más relevante. Esto puede lograrse mediante el uso de técnicas como PCA, T-SNE u otros algoritmos de reducción de dimensionalidad.
Por ejemplo, en el procesamiento de imágenes, los profesionales solían extraer manualmente características de la imagen, como los ojos, la nariz, los labios, etc. Estas características extraídas se alimentaban luego al modelo de clasificación.
El aprendizaje profundo, especialmente en las redes neuronales convolucionales, aborda este problema. La primera capa de una red neuronal aprende detalles más pequeños de la imagen, mientras que las capas siguientes combinan este conocimiento previo para formar información más compleja. En las redes neuronales convolucionales, la extracción de características se lleva a cabo utilizando filtros. La red aplica un filtro a la imagen para verificar si hay una coincidencia, es decir, si la forma de la característica es idéntica a alguna parte de la imagen. Si se encuentra una coincidencia, la red utiliza ese filtro. Por lo tanto, el proceso de extracción de características se realiza automáticamente.
Resumen:
La inteligencia artificial (IA) ha dotado a las máquinas con capacidad cognitiva. En comparación con el aprendizaje automático, los primeros sistemas de IA se basaban en la coincidencia de patrones y sistemas expertos.
El aprendizaje automático permite que las máquinas aprendan sin intervención humana. La máquina busca aprender cómo resolver una tarea dada a partir de los datos disponibles.
El aprendizaje profundo representa un avance significativo en el campo de la IA. Cuando se dispone de suficientes datos para el entrenamiento, el aprendizaje profundo logra resultados impresionantes, especialmente en el reconocimiento de imágenes y la traducción de textos. Esto se debe a que la extracción de características se realiza automáticamente en las diferentes capas de la red.
LECCIONES ANTERIORES:
- LECCION 1) ¿Qué es la Inteligencia Artificial? Introducción, Historia y Tipos de IA
- LECCION 2) Sistema Experto en IA: Aprende con Ejemplos
- LECCION 3) Aprendizaje Automático para Principiantes: Conceptos Básicos de ML
- LECCION 4) Matriz de Confusión en el Aprendizaje Automático: Aprende con Ejemplos
- LECCION 5 ) Aprendizaje Profundo para Principiantes: Proceso y Tipos
- LECCION 6 ) Aprendizaje Automático Supervisado: Algoritmos con Ejemplos
- LECCION 7) Aprendizaje Automático No Supervisado: Algoritmos, Tipos con Ejemplo
- LECCION 8) Red Neuronal de Retropropagación: Cómo Funciona el Algoritmo de Retropropagación
- LECCION 9) Aprendizaje por Refuerzo: Algoritmos, Tipos y Ejemplos
- LECCION 10)Tutorial de Lógica Difusa: Arquitectura, Aplicación, Ejemplo
- LECCION 11) Aplicaciones de la IA: 13 Ejemplos de IA que Debes Conocer y sus Diferencias
Siguiente lección :
LECCION12 ) Aprendizaje Supervisado vs Aprendizaje No Supervisado: Diferencias Clave
Mira Tambien